Abstract
This research introduces a novel approach for detecting defects in concrete structures. It utilizes the Gramian Angular Difference Field (GADF) in combination with a Convolutional Neural Network (CNN) enhanced by depthwise separable convolutions and attention mechanisms. The key contribution of this work is the use of GADF to transform one-dimensional impact-echo signals into two-dimensional images, thereby improving feature extraction and computational efficiency for analysis by the CNN. This advancement offers a new perspective in non-destructive testing technologies for concrete infrastructure. Comprehensive evaluation on a varied dataset of concrete structural defects reveals that our GADF-CNN model achieves an impressive test accuracy of 98.24 %, surpassing conventional models like VGG16, ResNet18, DenseNet, and ResNeXt50, and excelling in precision, recall, and F1-score metrics. Ultimately, this study enhances the integration of sophisticated image transformation techniques with deep learning, contributing to safer and more durable concrete infrastructure, and represents a noteworthy development in the field.
Highlights
- Novel GADF-CNN approach enhances concrete defect detection by transforming 1D impact-echo signals into 2D images.
- GADF-CNN achieves 98.24% accuracy, surpassing models like VGG16, ResNet18, DenseNet, and ResNeXt50.
- Integration of GADF and CNN with depthwise separable convolutions and attention mechanisms advances NDT methods.
1. Introduction
Concrete structures form a fundamental component of modern infrastructure, underpinning urban life through skyscrapers, bridges, and road networks. Their reliability is essential for safety, economic operations, and societal convenience [1]. Advances in measurement science are imperative for infrastructure safety assessments, as they enable the development of efficient, reliable, and non-destructive testing (NDT) methods that are crucial for maintaining the structural integrity of concrete structures [2], [3]. Among various NDT methods, the impact-echo technique has been widely acknowledged for its proficiency in detecting defects within concrete structures [4-7]. This non-invasive method utilizes acoustic resonances to identify structural anomalies, facilitating detailed internal assessments without causing damage [5].
With the advent of machine learning, there has been a significant shift towards enhancing the interpretative capabilities of impact-echo data. Machine learning has substantially improved the accuracy and reliability of data interpretation from impact-echo tests [8-11], leading to advancements in automating NDT and defect recognition in concrete structures [12], [13]. The evolution from machine learning to deep learning, particularly Convolutional Neural Networks (CNNs), has further expanded the possibilities in defect detection and classification [14-19]. However, conventional CNNs encounter limitations, notably substantial computational demands due to extensive convolution operations. To mitigate this, depthwise separable convolutions have been introduced, effectively reducing computational complexity without compromising performance [20-22]. Additionally, the implementation of attention mechanisms has enhanced the interpretative power of models by focusing on pertinent aspects of input data, a technique that has shown promise in various domains [23-25] These advancements have shown their potential across various fields, including neural machine translation and abstractive sentence summarization [24], [26].
Exploring the integration of advanced mathematical methods from related fields, could inspire novel approaches for defect detection [27], [28]. The Gramian Angular Difference Field (GADF), an innovative image transformation technique, stands out. Particularly effective in time-series data analysis, GADF excels in converting one-dimensional signals into two-dimensional images for subsequent processing through image analysis techniques, including CNNs [29-34]. The efficacy of GADF lies in its ability to retain temporal correlation in the transformed images, leveraging image recognition technology to enhance analytical capabilities. This study proposes the integration of GADF with CNNs, supplemented by depthwise separable convolutions and attention mechanisms, to potentially elevate defect detection in concrete structures. The presented framework combines GADF with a CNN-based depth network, aiming to refine the interpretation of impact-echo data, potentially leading to a more effective defect detection methodology.
The methodology presented herein is poised to make a substantive contribution to the domain of concrete structure defect recognition. It offers a robust, efficient, and resource-conservative alternative aimed at bolstering the safety and durability of concrete infrastructure. This novel approach is set to redefine benchmarks in Non-Destructive Testing (NDT) and evaluation of concrete structures, thereby facilitating the development of safer and more resilient urban environments. By integrating advanced mathematical methods with sophisticated machine learning algorithms, this research underscores a significant stride towards innovative NDT methodologies. The application of this method holds the potential not only to advance the current state of concrete defect detection but also to serve as a catalyst for further research in the field, offering a promising direction for future exploration. Furthermore, the key contributions of this research are summarized as follows:
1) The integration of GADF and CNN, supplemented by depthwise separable convolutions and attention mechanisms, has the potential to significantly enhance defect recognition processes in concrete structures.
2) The proposed methodology offers a robust and efficient tool with the potential to play a critical role in ensuring the safety and longevity of concrete infrastructure.
3) The proposed approach introduces a more accurate, expedient, and less resource-intensive method for the non-destructive testing and evaluation of concrete structures.
This paper is structured as follows: Section 2 presents our theoretical framework and methodology, elucidating on GADF, CNN Depth Network, Depthwise Separable Convolution, Attention Mechanisms, and our methodology for concrete structure defect recognition. Section 3 describes our experimental design, outlining the collection of impact echo data and our design for implementing a CNN with Depthwise Separable Convolutions and Attention Mechanisms. Section 4 offers our results and analysis, including a presentation of our findings, a comparative analysis with traditional and other machine learning methods, and a discussion of our findings. Section 5 concludes the paper by summarizing our key findings and suggesting potential future research directions in this field.
2. Theory and methodology
2.1. Gramian angular difference field
The GADF is a transformation technique that encodes time-series data into a 2D representation. The GADF is derived from the Gramian Angular Field (GAF), which is computed by mapping the time-series data into a polar coordinate system. The GAF is then computed as the outer product of the transformed data with itself.
To not bias the inner product towards the maximum observations, the time series X={x1,x2,⋯,xn} is scaled into the interval [–1, 1]. This can be achieved by applying the following transformation:
where X' is the scaled time series, min(X) and max(X) are the minimum and maximum values of the time series, respectively.
The scaled time series is then converted to polar coordinates. The radial coordinate r is computed as the absolute value of the scaled time series X', and the angular coordinate θ is computed as:
The GAF is computed as the outer product of the angular coordinates with themselves:
where ⊗ denotes the outer product operation.
The Gramian Angular Summation Field (GASF) and the GADF are both image transformation techniques that convert one-dimensional time series data into two-dimensional images. While GASF captures temporal correlations by using the sum of the phase space, GADF emphasizes changes in the data by using the difference of the phase space. The GASF and GADF can be computed using the following equations:
where θi and θj are the angular coordinates of the ith and jth data points, GASF(i,j) and GADF(i,j) are the elements of the GASF and GADF, respectively.
In certain scenarios, the GADF demonstrates superior performance over the GASF, attributable to its emphasis on data variation. This attribute is particularly beneficial in applications where change detection is critical, such as in the identification of defects in concrete structures. Consequently, the GADF technique has been utilized in this research. It effectively converts time-series data into a two-dimensional format, thereby augmenting the model's capacity to discern and assimilate these pivotal variations.
2.2. The CNN depth network
A CNN is composed of several types of layers, each performing a specific operation on the input data. These layers include convolutional layers, pooling layers, fully connected layers, and a classifier layer [35], [36].
Convolutional layers apply a set of learnable filters to the input data. Each filter is convolved across the width and height of the input to produce a feature map. This operation can be represented mathematically as:
where Yl-1,i+m,j+n is the input from the (l-1)th layer at location (i+m,j+n), Wl,m,n and b are the weights and bias of the lth layer, * is the convolution operation, Yl,i,j is the output of the lth layer at location (i,j), fl is the activation function of the lth layer.
Pooling layers reduce the spatial dimensions of the input, typically using a max or average operation. This operation can be represented mathematically as:
where P is the pooling region.
Fully connected layers, also known as dense layers, connect every neuron in the layer to every neuron in the previous layer. This operation can be represented mathematically as:
where Yl,i is the input from (l-1)th layer, Wl,i,j and bl,i are the weights and bias of the lth layer, Yl,i is the output of the lth layer at location i, fl is the activation function of the lth layer.
The final layer of the CNN is typically a classifier layer that uses a SoftMax function to output a probability distribution over the classes. This operation can be represented mathematically as:
where YL-1,i is the input from the (L-1)th layer, YL,i is the output of the Lth layer (classifier layer) at location i.
2.3. Depthwise separable convolution and attention mechanisms
In the quest to improve the performance of our CNN model for concrete structure defect recognition, we incorporate two advanced concepts: Depthwise Separable Convolution and Attention Mechanisms. These techniques are aimed at enhancing the model's ability to learn more complex and abstract features from the GADF-transformed data, while also improving computational efficiency.
Depthwise Separable Convolution is a variant of the standard convolution operation that is used in traditional CNN. It involves two separate operations: a depthwise convolution followed by a pointwise convolution. This operation can be represented mathematically as:
where Yl-1,i+m,j+n is the input from the (l-1)th layer at location (i+m,j+n), Wl,m,n and bl are the weights and bias of the lth layer, ⋅ is the convolution operation, Yl,i,j is the output of the lth layer at location (i,j), fl is the activation function of the lth layer. The depthwise convolution applies a single filter to each input channel.
The pointwise convolution then applies a 1×1 convolution to combine the outputs of the depthwise convolution. This operation reduces the computational cost and model size compared to standard convolutions, making the model more efficient and faster to train.
Attention Mechanisms, on the other hand, allow the model to focus on the most relevant parts of the input for making predictions. In the context of our task, this means that the model can learn to pay more attention to the parts of the GADF-transformed data that are most indicative of a defect in the concrete structure.
The attention mechanism can be represented mathematically as:
where Yl-1,j is the input from the (l-1)th layer, Wl,i,j and bl,i are the weights and bias of the lth layer, Yl,i is the output of the lth layer at location i, fl is the activation function of the lth layer.
The use of Depthwise Separable Convolution and Attention Mechanisms in the CNN depth network enhances the network's ability to recognize defects in concrete structures. This dual incorporation not only enhances the model's ability to learn complex and abstract features from the GADF-transformed data, but also improves computational efficiency, making it a powerful tool for concrete structure defect recognition.
2.4. Developing methodology for concrete structure defect recognition
In the development of a comprehensive methodology for concrete structure defect recognition, the integration of the GADF and the CNN depth network, enhanced with Depthwise Separable Convolution and Attention Mechanisms, is crucial. This section outlines the process of integrating these components into a cohesive methodology (Fig. 1).
Fig. 1Methodology for concrete structure defect recognition
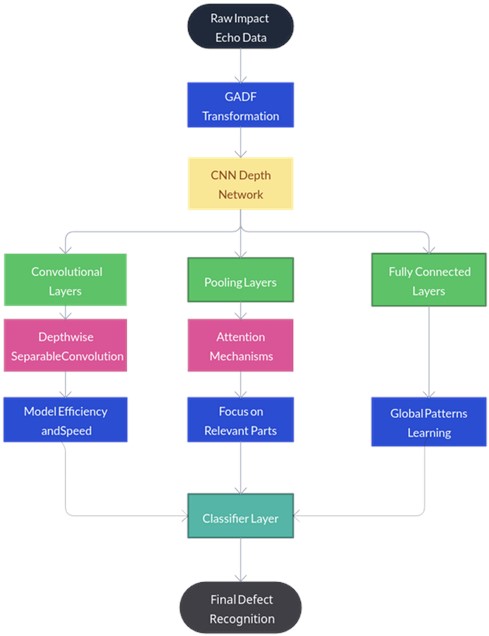
The first step in our methodology is the application of the GADF transformation to the raw impact echo data. This transformation, as detailed in Section 2.1, encodes the time-series data into a 2D representation. The GADF transformation serves to enhance the spatial-temporal features of the data, effectively converting the impact echo data into an image-like format. This conversion is a critical step as it allows the subsequent CNN to process the data effectively.
Once the data has been transformed using the GADF, it is input into the CNN depth network. The CNN, as discussed in Section 2.2, consists of several layers, each performing a specific operation on the input data. The convolutional layers apply a set of learnable filters across the width and height of the input data, producing a feature map. The pooling layers reduce the spatial dimensions of the data, summarizing the extracted features over spatial regions. The fully connected layers connect every neuron in one layer to every neuron in the previous layer, learning global patterns in the data. The classifier layer outputs a probability distribution over the classes, providing the final defect recognition results.
To optimize the performance and efficiency of the CNN model, this study integrates Depthwise Separable Convolution and Attention Mechanisms, as detailed in Section 2.3. Depthwise Separable Convolution minimizes computational demands and model dimensions, thus enhancing efficiency and expediting the training process. Conversely, Attention Mechanisms enable the model to concentrate on the most salient segments of the input for prediction purposes. The model is trained to prioritize areas in the GADF-transformed data that most strongly indicate defects in concrete structures.
For the computational implementation, Python version 3.8 and PyTorch were utilized to develop and test the neural networks, providing a robust framework for the efficient execution of large-scale numerical computations. For benchmarking, the model's performance was evaluated against established methods using the Impact Echo dataset, recognized for its relevance in the field of non-destructive testing in concrete structures. The experimental design for the Impact Echo dataset is detailed in Section 3.
Summarily, the integration of the GADF transformation, the CNN depth network, and the Depthwise Separable Convolution and Attention Mechanisms forms the basis of the methodology for concrete structure defect recognition. This integration leverages the strengths of each component, resulting in a powerful model capable of accurately recognizing defects in concrete structures.
3. Experimental design
The experimental design for our research on concrete structure defect recognition is a critical aspect of our methodology. It involves studying collecting impact echo data, and designing a CNN with Depthwise Separable Convolutions and Attention Mechanisms. This section outlines the process involved in each of these stages, drawing on relevant literature to inform our approach.
3.1. Collection of impact echo data
The experimental setup began with the creation of multiple concrete slabs, each incorporating a range of potential defects. In a controlled laboratory setting, two concrete model specimens were fabricated, designed to simulate four distinct internal defect scenarios: intact structure, non-compact areas, voids, and water-filled voids. Each model was constructed with dimensions of 150 cm in height, 220 cm in length, and a variable thickness of 60 to 70 cm. Hollow cylinders with a diameter of 20 cm were embedded in the specimens to replicate void defects. These cylinders were either left vacant to represent air voids or filled with water to simulate water-filled voids. For non-compact defect emulation, the cylinders were filled with loosely packed materials. The defects were strategically placed at varying depths (10 cm, 20 cm, 30 cm, and 40 cm) within the specimens to accurately represent possible real-world defect scenarios. Detailed visual documentation of the construction process of these models is presented in Fig. 2.
The next phase of the research involved acquiring impact echo data. The equipment for these tests, including a steel ball array, a handheld transducer, a data acquisition (DAQ) system, and a computer with specialized analytical software, was sourced from IEI, LLC in Ithaca, NY, USA. Precise adjustment of signal sampling frequency and length was crucial for the success of the impact-echo tests. These parameters were instrumental in accurately capturing the impact-echo signal with maximum response frequency, thereby ensuring optimal sampling resolution. Guided by the physical properties of the specimens, the sampling frequency was set at 500 kHz and the sampling length at 1024. The testing process entailed generating stress waves by striking the concrete surface with an impactor, followed by using a sensor to record the reflected waves. This procedure was systematically repeated across various points on the concrete structure to amass a comprehensive dataset. This approach yielded a total of 830 samples, each categorized into one of the four predefined internal defect types: sound, non-compact, voids, and water-filled [18].
Following the data collection, the data undergoes several preprocessing steps. These steps are integral to the process and include normalization, and segmentation.
Normalization ensures that the data is in a suitable format for the subsequent steps. This is done by scaling the data to have a zero mean and unit variance, which can be represented as:
where μ and σ are the mean and standard deviation of the noise-reduced data, respectively, X''(t) is the normalized data.
Fig. 2Preparation of experimental concrete slabs: a) constructing the concrete specimen mold; b) the concrete slab specimens after they have been poured

a)

b)
Segmentation divides the data into manageable chunks that can be processed individually. This can be represented as:
where i is the segment index, T is the segment length, Xi(t) is the ith segment of the normalized data. The collected impact echo data will serve as the input for our CNN model after preprocessing steps.
3.2. Design for implementing CNN with depthwise separable convolutions and attention mechanisms
A pivotal aspect of the experimental design is the deployment of a CNN integrated with Depthwise Separable Convolutions and Attention Mechanisms. The CNN is engineered to process the impact echo data, which is transformed into a two-dimensional format using the GADF. The architecture of the CNN encompasses various layers: convolutional layers augmented with Depthwise Separable Convolutions, pooling layers complemented by Attention Mechanisms, fully connected layers, and a classifier layer, as depicted in Fig. 3. The construction of the CNN adheres to the principles delineated in the methodology section (Section 2).
Fig. 3The architecture of CNN with depthwise separable convolutions and attention mechanisms
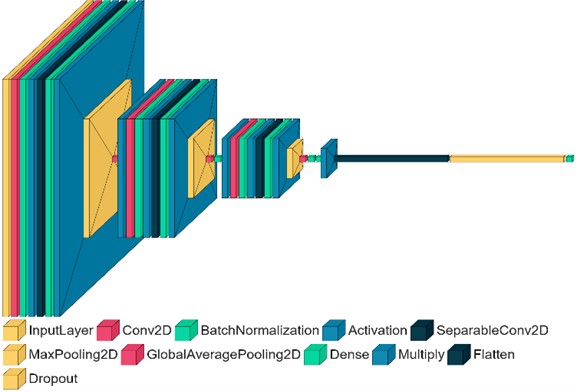
The model architecture is composed of a sequence of layers that sequentially process the input data. Initially, a series of DepthwiseSeparableConv layers are applied, each of which is followed by batch normalization, a ReLU activation function, and max pooling. These layers are primarily responsible for feature extraction from the input data. Subsequently, an AttentionModule is incorporated after each max pooling layer. These modules enhance the model's capability to focus on the most relevant features. To prevent overfitting during the training phase, a dropout layer is included, which randomly sets a fraction of input units to zero at each update. Finally, a fully connected (Linear) layer is employed to transform the extracted features into a set of class scores, completing the model architecture. Table 1 summarize the parameter settings of each layer in the model architecture:
Table 1Parameter settings of the proposed CNN model architecture
Layer Type | Parameters |
Depthwise separable conv | in_channels = 3, out_channels = 32, kernel_size = 3, padding = 1 |
Batch normalization | num_features = 32 |
ReLU | inplace = True |
Max pooling | kernel_size = 2 |
Attention module | in_channels = 32, out_channels = 32, reduction_ratio = 8 |
Depthwise separable conv | in_channels = 32, out_channels = 64, kernel_size = 3, padding = 1 |
Batch normalization | num_features = 64 |
ReLU | inplace = True |
Max pooling | kernel_size = 2 |
Attentionmodule | in_channels = 64, out_channels = 64, reduction_ratio = 8 |
Depthwise separable conv | in_channels = 64, out_channels = 128, kernel_size = 3, padding = 1 |
Batch normalization | num_features = 128 |
ReLU | inplace = True |
Max pooling | kernel_size = 2 |
Attention module | in_channels = 128, out_channels = 128, reduction_ratio = 8 |
Dropout | p = 0.5 |
Fully connected (linear) | in_features = 1282828, out_features = num_classes |
In the machine learning model's training process, each category's samples are divided into three parts (the training set, the validation set, and the testing set) according to the ratio of 4:1:1. The defect samples included: 1200 sound samples, 1200 non-compact samples, 1200 voids samples, and 1200 water-filled samples. The dataset is shown in Table 2.
Table 2The distribution of training set, the validation set, and the testing set
Defect types | Label | Training set | Validation set | Testing set |
Sound | 0 | 800 | 200 | 200 |
Non-compact | 1 | 800 | 200 | 200 |
Voids | 2 | 800 | 200 | 200 |
Water filled | 3 | 800 | 200 | 200 |
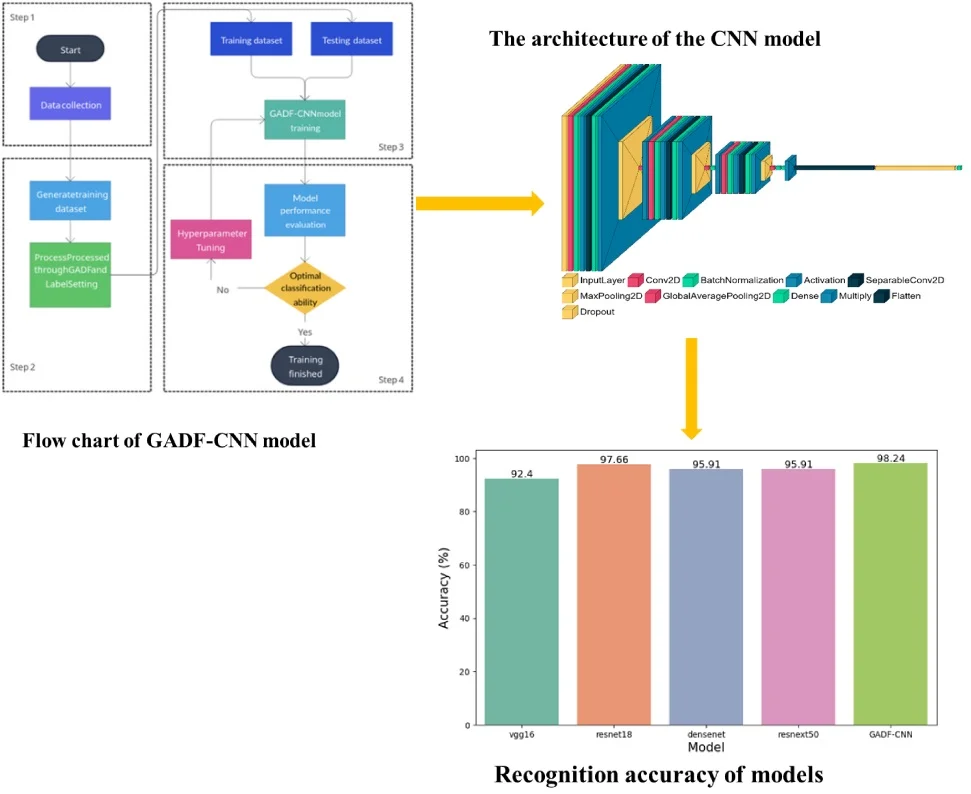
Fig. 4Flow chart of GADF-CNN model training and application
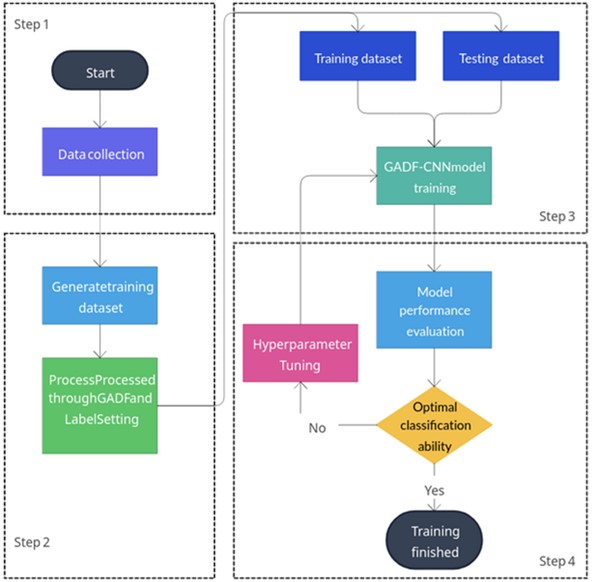
The concrete defect classification steps based on GADF-CNN are shown in Fig. 4. The specific steps are as follows:
1) Use the impact echo instrument to detect different types of concrete structures with defects on-site, collect the impact echo vibration signals to form the original dataset for the model, and preprocess the raw data.
2) Process the preprocessed raw dataset with GADF and label it to generate the sample set for the model.
3) To train the GADF-CNN model, randomly sample all sets of data and divide them into training and test sets in an 8:2 ratio. Feed these sets to the model to complete the training process. Save the weight file when the classification accuracy reaches its highest point during the training process.
4 After the model training is completed, adjust the model's hyperparameters based on its performance on the test set, and retrain the GADF-CNN model until it performs best on the test set, i.e., the model reaches the ideal state.
The following pseudo-code provides a detailed description of the GADF-CNN Processing Algorithm, highlighting its key components and operations.
Table 3Algorithm: GADF-CNN processing algorithm
Input: Image-like GADF-transformed data X Output: Defect recognition results Y 1: procedure GADF-CNN(X) 2: // Step 1: Define the Depthwise Separable Convolution 3: function DEPTHWISESEPARABLECONV(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, bias=False) 4: depthwise = Conv2d(in_channels, in_channels, kernel_size, stride, padding, dilation, groups=in_channels, bias=bias) 5: pointwise = Conv2d(in_channels, out_channels, 1, 1, 0, 1, 1, bias=bias) 6: return depthwise, pointwise 7: end function 8: 9: // Step 2: Define the Attention Mechanism 10: function ATTENTIONMODULE(in_channels, out_channels, reduction_ratio=8) 11: avg_pool = AdaptiveAvgPool2d(1) 12: fc1 = Linear(in_channels, in_channels // reduction_ratio, bias=False) 13: relu = ReLU() 14: fc2 = Linear(in_channels // reduction_ratio, out_channels, bias=False) 15: sigmoid = Sigmoid() 16: return avg_pool, fc1, relu, fc2, sigmoid 17: end function 18: 19: // Step 3: Define the GADF-CNN model 20: function GADF_CNN(num_classes) 21: features = Sequential( 22: DEPTHWISESEPARABLECONV(3, 32, 3, padding=1), 23: BatchNorm2d(32), 24: ReLU(inplace=True), 25: MaxPool2d(2), 26: ATTENTIONMODULE(32, 32), 27: DEPTHWISESEPARABLECONV(32, 64, 3, padding=1), 28: BatchNorm2d(64), 29: ReLU(inplace=True), 30: MaxPool2d(2), 31: ATTENTIONMODULE(64, 64), 32: DEPTHWISESEPARABLECONV(64, 128, 3, padding=1), 33: BatchNorm2d(128), 34: ReLU(inplace=True), 35: MaxPool2d(2), 36: ATTENTIONMODULE(128, 128), 37: ) 38: classifier = Sequential( 39: Dropout(0.5), 40: Linear(128 * 28 * 28, num_classes), 41: ) 42: return features, classifier 43: end function 44: 45: // Step 4: Forward propagation 46: function FORWARD(X) 47: X = features(X) 48: X = X.view(X.size(0), -1) 49: Y = classifier(X) 50: return Y 51: end function 52: end procedure |
4. Results and analysis
4.1. Presentation of the results
In the evaluation of the proposed methodology, several metrics were used to assess the model's performance. These include the accuracy rate (Acc), recall rate (Rec), F1 score (F1), and confusion matrix (CM).
The accuracy rate (Acc) is a measure of the proportion of total predictions that are correct. It is calculated using the formula:
where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, FN is the number of false negatives.
The recall rate (Rec), also known as sensitivity or true positive rate, is the proportion of actual positive cases that were correctly identified. It is calculated as:
The F1 score (F1) is the harmonic mean of precision and recall, providing a balance between these two metrics. It is calculated as:
where Precision is the proportion of positive identifications that were actually correct, calculated as:
The confusion matrix (CM) is a robust tool for evaluating classification model performance, providing a detailed breakdown of correct and incorrect predictions across different classes. It organizes predictions into a tabular format, with rows representing predicted classes and columns denoting actual classes. Correct predictions populate the matrix’s diagonal, while off-diagonal elements signify errors. Through a comprehensive analysis of the CM, one can discern the error types prevalent in the classifier's performance, thereby illuminating potential avenues for model improvement.
Throughout the model training process, performance metrics were evaluated on a training dataset at the completion of each epoch. The training utilized a batch size of 32, allowing for efficient processing and model weight updates. The Adam optimizer, with a learning rate of 0.0001, facilitated gradual and stable improvements in model performance. To prevent overfitting, a regularization strategy involving a dropout rate of 0.5 was applied within the classifier. This approach was chosen based on its proven effectiveness in enhancing generalizability while maintaining model simplicity.
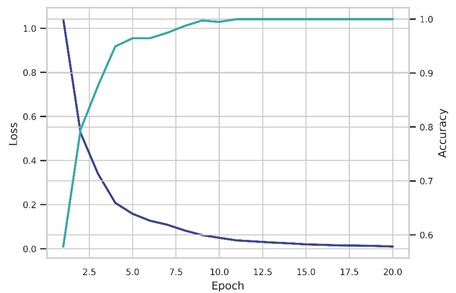
As training progressed over 20 epochs, the model demonstrated improved accuracy and reduced loss, as depicted in Fig. 5. This iterative process allowed for continuous refinement of the model’s weights, ensuring that each epoch contributed to the model's ability to discern intricate patterns within the dataset. The training was implemented on a T4 GPU and took 30.748 seconds, further supporting that the proposed model is a less resource-intensive method for concrete structure defect recognition. The combination of strategic parameter selection and advanced hardware utilization underscores the model's efficiency and effectiveness in identifying defects within concrete structures.
Fig. 5Illustration of loss value and accuracy curves over time
The final performance of the model on the testing set for each of the four categories of concrete defects is summarized in Table 4.
Table 4Performance of the model on the testing set
Defect category | Precision | Recall | F1 score | Accuracy |
Sound | 0.9607 | 1.0000 | 0.9800 | 0.9824 |
Non-compact | 1.0000 | 1.0000 | 1.0000 | |
Voids | 1.0000 | 0.9500 | 0.9743 | |
Water filled | 0.9743 | 0.9500 | 0.9620 |
Table 4 presents the performance metrics of the proposed model for four categories of concrete defects. The model exhibits high precision, recall, and F1 scores across all categories, indicating its effectiveness in accurately identifying and classifying defects. For instance, the “Sound” category achieved a precision of 0.9607 and a perfect recall of 1.0000. The “Non-compact” category achieved perfect scores across all metrics. Despite slightly lower recall rates in the 'Voids' and “Water filled” categories, the overall accuracy of the model remains high, affirming the model's robustness in concrete structure defect recognition.
The corresponding confusion matrix for the model’s predictions on the testing set is provided in Fig. 6.
Fig. 6The confusion matrix of four category’s internal defects
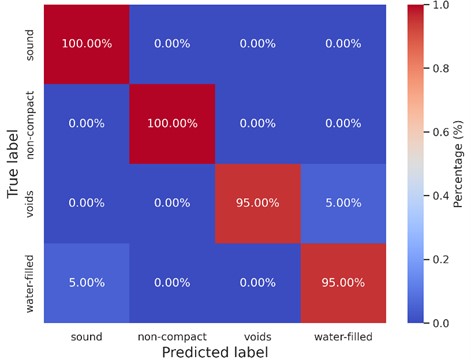
The confusion matrix offers a visual insight into the model’s performance. Each row signifies the instances in a predicted class, while each column represents the instances in an actual class. The diagonal elements indicate correct predictions, while off-diagonal elements represent misclassifications. The matrix reveals a high degree of accuracy, with most misclassifications occurring between the “Voids” and “Water filled” categories.
4.2. Evaluation of statistical indicators
Evaluating the performance and reliability of the GADF-CNN approach for defect detection necessitates a comprehensive assessment of statistical indicators such as uncertainty, sensitivity, and confidence intervals. These metrics are essential for understanding the limitations and potential issues related to the model's measurements, which can be influenced by factors like input data noise, defect characteristic variations, and model architecture limitations. Sensitivity analysis identifies the impact of these factors on the model's outputs, while confidence intervals provide a statistical range for the true performance metrics, considering the inherent variability in the measurements.
Monte Carlo Dropout (MCD) is a technique for estimating prediction uncertainty in CNN models. It involves performing multiple forward passes through the network with dropout enabled during inference. The dropout layers randomly set a fraction of the neurons to zero, creating an ensemble of subnetworks. The prediction uncertainty is estimated by calculating the mean and variance of the outputs across the ensemble. The formula for MCD is:
where ˆy is the mean prediction, ˆσ2 is the variance, T is the number of forward passes, and ˆyt is the prediction of the tth subnetwork.
Estimating prediction uncertainty in GADF-CNN models using Monte Carlo Dropout involves performing multiple forward passes with dropout enabled. The mean and standard deviation of the predictions across the passes are calculated to obtain the expected output and the uncertainty associated with each prediction. In this example, the average uncertainty of 0.0072 indicates that the model has a high level of confidence in its predictions, with low variability across the multiple forward passes. This low average uncertainty value suggests that the model's predictions are consistent and reliable.
To estimate the confidence interval of the GADF-CNN model's performance metrics, bootstrap sampling can be employed. The process involves randomly sampling the dataset with replacement to create multiple bootstrap samples, training the model on each sample, and calculating the performance metrics for each trained model. The formula for the confidence interval is:
where μ is the mean of the performance metric across all bootstrap samples, σ is the standard deviation, n is the number of bootstrap samples, and z* is the critical value from the standard normal distribution corresponding to the desired confidence level.
The confidence interval of the GADF-CNN model's performance metrics can be implemented using bootstrap resampling. It randomly samples the dataset, trains the model on each sample, and calculates precision. The 95 % confidence interval is then computed using the 2.5th and 97.5th percentiles of the bootstrap results. In this case, the accuracy confidence interval is (0.950, 0.994), indicating that the true accuracy of the model is to fall within this range with 95 % confidence.
Sensitivity analysis of the GADF-CNN model involves evaluating its performance when the testing dataset is subjected to varying levels of noise, measured by Signal-to-Noise Ratio (SNR). The model's sensitivity to noise is assessed by calculating the performance metrics, such as accuracy, precision, recall, and F1 score, at different SNR values. The SNR is defined as:
where Psignal is the power of the original signal and Pnoise is the power of the added noise. The noise can be generated using a Gaussian distribution with zero mean and a specified standard deviation, determined by the desired SNR. The model's performance is then evaluated at each SNR level to assess its sensitivity to noise.
Fig. 7Signal quality vs. detection accuracy
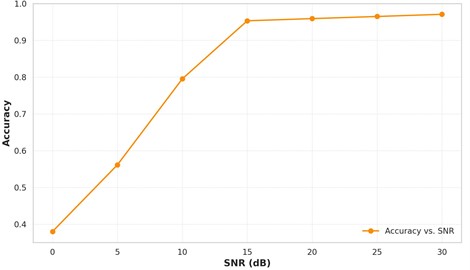
The sensitivity analysis of the GADF-CNN model evaluates its performance under different Signal-to-Noise Ratio (SNR) levels. Gaussian noise is added to the input data based on the specified SNR, and the model’s accuracy is calculated for each SNR level. The results show that the model's accuracy improves as the SNR increases, demonstrating its sensitivity to noise (Fig. 7). At an SNR of 30 dB, the model achieves an accuracy of 0.9708, indicating its robustness to high-quality signals.
In summary, evaluating statistical indicators is crucial for assessing the GADF-CNN approach’s performance and reliability in defect detection. Uncertainty quantification, confidence interval estimation, and sensitivity analysis provide insights into the model’s confidence, accuracy range, and robustness to noise. These indicators collectively offer a comprehensive understanding of the model’s performance, limitations, and potential issues, enabling informed decision-making for real-world applications. The results demonstrate the model’s high consistency, reliability, and accuracy, particularly in high-quality signal scenarios.
4.3. Comparative evaluation of defect recognition models
In this study, a comprehensive comparative analysis was conducted to evaluate five distinct models designed for detecting defects in concrete structures. These models encompass the established architectures of vgg16, resnet18, densenet, resnext50, and the newly developed GADF-CNN model. To ensure equitable comparison, all conventional models – vgg16, resnet18, densenet, and resnext50 – were initialized with pre-trained parameters, utilizing transfer learning from the dataset in question. The training and testing of all models were performed on the NVIDIA Tesla T4 GPU. The results of the defect detection models are illustrated in Fig. 8 and 9.
The initial model evaluated was vgg16, which recorded a training duration of 112.37 seconds and achieved a test accuracy of 92.40 %. Despite its high accuracy, vgg16 exhibited the longest training time among the models evaluated. Subsequently, the resnet18 model underwent training and testing, requiring 31.43 seconds. While faster in training compared to vgg16, it also demonstrated a notable increase in test accuracy to 97.66 %. The densenet and resnext50_32x4d models were next in the sequence of evaluation. The densenet model required 84.45 seconds for training and attained a test accuracy of 95.91 %. In comparison, the resnext50_32x4d model took a marginally longer training time of 110.66 seconds, achieving an identical test accuracy of 95.91 %. Lastly, the newly developed GADF-CNN model was assessed. Its training time was 30.75 seconds, slightly quicker than resnet18 and significantly faster than the other models. Notably, the GADF-CNN model surpassed all other models in test accuracy, reaching 98.24 %.
Fig. 8Training time of vgg16, resnet18, densenet, resnext50, and GADF-CNN
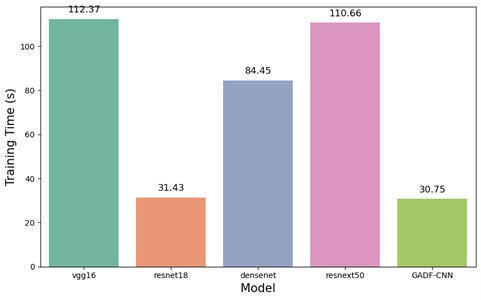
Fig. 9Recognition accuracy of vgg16, resnet18, densenet, resnext50, and GADF-CNN
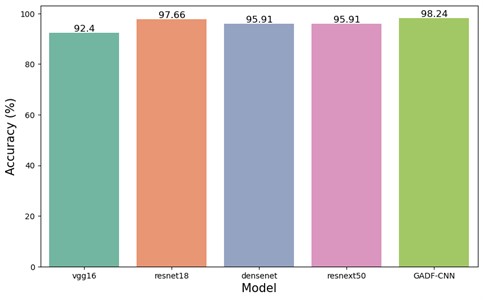
The results indicate that the GADF-CNN model surpasses other models in terms of accuracy and achieves this enhanced performance within a shorter training duration. Consequently, GADF-CNN demonstrates a commendable synergy between computational efficiency and predictive accuracy, establishing its potential as an effective and efficient tool for detecting defects in concrete structures. These findings bolster the assertion that the amalgamation of GADF with a CNN-based depth network, enhanced by Depthwise Separable Convolutions and Attention Mechanisms, leads to a more advanced, precise, and efficient approach for non-destructive testing and evaluation of concrete structures.
To provide additional context for the performance of the GADF-CNN model, a comparative analysis was conducted against a range of methods documented in existing literature. Table 5 presents a summary of the performance metrics of these methods applied to various datasets. The table includes a comparative evaluation of different defect recognition methods for concrete structures, assessed using accuracy, recall, precision, and F1-score metrics. The methods evaluated encompass the Naive Bayes classifier, Support Vector Machines (SVM), standard Convolutional Neural Networks, 1D Convolutional Neural Networks, and the GADF-CNN.
Table 5Performance comparison of different methods for concrete structure defect recognition using impact echo data
Method | Accuracy | Recall | Precision | F1-score |
Naive Bayes classifier [10] | 0.92 | 0.91 | 0.92 | 0.92 |
SVM [13] | 0.88 | – | – | – |
Convolutional neural networks [14] | 0.94 | – | – | – |
Convolutional neural networks [16] | 0.96 | – | – | – |
1D Convolutional neural networks [18] | 0.91 | 0.92 | 0.91 | 0.91 |
GADF-CNN | 0.98 | 0.97 | 0.97 | 0.98 |
Analysis of Table 5 reveals that the Naive Bayes classifier, as investigated by Jafari et al. [10], demonstrates robust performance with an overall score of 0.92. However, its foundational assumption of feature independence may limit its applicability to more intricate datasets. The SVM application by Dorafshan et al. [13] yields an accuracy of 0.88, but the absence of additional metrics precludes a comprehensive assessment. SVM’s effectiveness is notably dependent on kernel selection and may be less suitable for large, multi-class datasets. Convolutional Neural Network approaches, as reported in studies [14] and [16], achieve accuracies of 0.94 and 0.96, respectively, illustrating the potential of deep learning in this field. However, the lack of complete metric evaluation hinders a full appraisal of these models. The 1D Convolutional Neural Network implemented by Xu et al. [18] exhibits consistent results across metrics, achieving 0.91, which highlights the efficacy of CNNs in processing 1D data. The GADF-CNN model, in contrast, surpasses these with an accuracy of 0.98 and high recall, precision, and F1-score metrics (0.97, 0.97, and 0.98, respectively). This model adeptly merges GADF image transformation with CNN, enhancing defect detection in impact-echo data.
The incorporation of the GADF alongside CNN represents a notable advancement in the realm of non-destructive testing and measurement science at large. By merging sophisticated image transformation techniques with the capabilities of deep learning, this method has demonstrated exceptional efficacy in identifying defects within concrete structures, evidenced by its exemplary performance across accuracy, precision, recall, and F1 score metrics. These outcomes not only highlight the synergy between mathematical methodologies and machine learning in elevating the precision and reliability of engineering measurements but also suggest a promising direction for future research in this interdisciplinary field.
Moreover, the implications of the GADF-CNN technique extend considerably beyond the realm of detecting concrete imperfections. Its validated efficacy establishes a foundation for the adoption of analogous approaches within diverse sectors of measurement science and technology, especially for the intricate data analysis required in the upkeep of essential infrastructure elements like bridges, tunnels, and pavements. Such broad applicability signals the method’s potential to fundamentally transform the methodologies employed in the critical inspection and maintenance of infrastructure. In addition, the model's computational efficiency, achieved through the use of depthwise separable convolutions, is in line with the ongoing objective to devise analytical tools that are both less resource-intensive and highly effective, particularly pertinent for extensive or real-time monitoring endeavors. This strategy not only propels the field of measurement science forward by facilitating quicker and more scalable monitoring solutions but also underscores the significance of sensitivity analysis in ascertaining the robustness and dependability of these measurement systems. Consequently, while the GADF-CNN model has established a new benchmark in concrete defect detection, its contribution to the evolution of measurement tools is profound, fostering the development of safer, more enduring, and resilient infrastructural frameworks.
5. Conclusions
This research introduces a novel approach for defect detection in concrete structures, employing a synergistic combination of the GADF and a CNN enhanced with depthwise separable convolutions and attention mechanisms. The GADF method is utilized to transform impact echo data into a 2D representation, which is then processed by the CNN. This integration notably improves feature extraction and increases computational efficiency. The proposed model undergoes a thorough evaluation on a diverse dataset, comprising impact echo data from various types of concrete structures with defects. It is also comparatively analyzed against several established methodologies. Key conclusions drawn from this study include:
1) The integration of the Gramian Angular Difference Field (GADF) with a Convolutional Neural Network (CNN), enhanced by depthwise separable convolutions and attention mechanisms, exhibits a significant improvement in detecting defects in concrete structures.
2) The developed model emerges as a potent and efficient tool, potentially contributing to the preservation and extension of the lifespan of concrete infrastructures.
3) The method presents a swift, accurate, and less resource-intensive alternative for non-destructive testing and evaluation of concrete structures, representing a notable advancement in the field.
4) The established framework outperforms various existing methods in accuracy, recall, precision, F1-score, and training time, as evidenced by testing on a dataset comprising impact echo data from diverse types of defective concrete structures.
Looking ahead, the field of research in concrete structure defect detection presents a wealth of diverse and promising opportunities. Future empirical studies, incorporating a variety of challenging datasets, are expected to shed light on the full capabilities and potential limitations of the proposed model. Expanding the dataset with more diverse defect types and conditions could further validate and improve the model's robustness. Investigating the integration of GADF-CNN with other non-destructive testing methods could offer a more comprehensive defect detection approach. Additionally, the application of advanced deep learning techniques, such as transfer learning or generative adversarial networks, could potentially enhance the model's performance further. Exploring advanced deep learning techniques like transfer learning and generative adversarial networks might enhance adaptability and performance across different concrete structures and defects. Integrating other non-destructive testing methods with the proposed approach may lead to a more comprehensive solution for defect detection in concrete structures. This research underscores the significant potential of combining advanced image transformation techniques with deep learning models for the crucial task of identifying defects in concrete structures. While the current methodology shows promising results, ongoing refinement is essential to fully exploit its potential in the field of non-destructive testing and evaluation, ultimately contributing to the safety and durability of built infrastructures.
References
-
M. Holický and M. Sýkora, “Reliability approaches affecting the sustainability of concrete structures,” Sustainability, Vol. 13, No. 5, p. 2627, Mar. 2021, https://doi.org/10.3390/su13052627
-
S. K. Dwivedi, M. Vishwakarma, and P. A. Soni, “Advances and researches on non destructive testing: a review,” Materials Today: Proceedings, Vol. 5, No. 2, pp. 3690–3698, Jan. 2018, https://doi.org/10.1016/j.matpr.2017.11.620
-
B. Wang, S. Zhong, T.-L. Lee, K. S. Fancey, and J. Mi, “Non-destructive testing and evaluation of composite materials/structures: a state-of-the-art review,” Advances in Mechanical Engineering, Vol. 12, No. 4, p. 168781402091376, Apr. 2020, https://doi.org/10.1177/1687814020913761
-
Y. J. Yan, L. Cheng, Z. Y. Wu, and L. H. Yam, “Development in vibration-based structural damage detection technique,” Mechanical Systems and Signal Processing, Vol. 21, No. 5, pp. 2198–2211, Jul. 2007, https://doi.org/10.1016/j.ymssp.2006.10.002
-
M. J. Sansalone and W. B. Streett, Impact-Echo. Nondestructive Evaluation of Concrete and Masonry. USA: Bullbrier Press, 1997.
-
N. J. Carino, “The impact-echo method: an overview,” in Proceedings of the Structures, May 2001, https://doi.org/10.1061/40558
-
C. Hsiao, C.-C. Cheng, T. Liou, and Y. Juang, “Detecting flaws in concrete blocks using the impact-echo method,” NDT and E International, Vol. 41, No. 2, pp. 98–107, Mar. 2008, https://doi.org/10.1016/j.ndteint.2007.08.008
-
Y.-J. Cha, T. Epp, and D. Svecova, “Automated air-coupled impact echo based non-destructive testing using machine learning,” in Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, Vol. 10598, pp. 401–407, Mar. 2018, https://doi.org/10.1117/12.2295947
-
A. Sengupta, S. Ilgin Guler, and P. Shokouhi, “Interpreting impact echo data to predict condition rating of concrete bridge decks: a machine-learning approach,” Journal of Bridge Engineering, Vol. 26, No. 8, p. 04021, Aug. 2021, https://doi.org/10.1061/(asce)be.1943-5592.0001744
-
F. Jafari and S. Dorafshan, “Bridge inspection and defect recognition with using impact echo data, probability, and Naive Bayes classifiers,” Infrastructures, Vol. 6, No. 9, p. 132, Sep. 2021, https://doi.org/10.3390/infrastructures6090132
-
J. Igual, A. Salazar, G. Safont, and L. Vergara, “Semi-supervised Bayesian classification of materials with impact-echo signals,” Sensors, Vol. 15, No. 5, pp. 11528–11550, May 2015, https://doi.org/10.3390/s150511528
-
H. Shimbo, T. Mizobuchi, and J.-I. Nojima, “Application of image recognition technology to sound spectrogram of impact-echo method,” in Proceedings of the Structural Health Monitoring 2019, Nov. 2019.
-
F. Jafari and S. Dorafshan, “Comparison between supervised and unsupervised learning for autonomous delamination detection using impact echo,” Remote Sensing, Vol. 14, No. 24, p. 6307, Dec. 2022, https://doi.org/10.3390/rs14246307
-
S. Dorafshan and H. Azari, “Evaluation of bridge decks with overlays using impact echo, a deep learning approach,” Automation in Construction, Vol. 113, p. 103133, May 2020, https://doi.org/10.1016/j.autcon.2020.103133
-
S. Dorafshan and H. Azari, “Deep learning models for bridge deck evaluation using impact echo,” Construction and Building Materials, Vol. 263, p. 120109, Dec. 2020, https://doi.org/10.1016/j.conbuildmat.2020.120109
-
J. Xu and X. Yu, “Detection of concrete structural defects using impact echo based on deep networks,” Journal of Testing and Evaluation, Vol. 49, No. 1, pp. 109–120, Jan. 2021, https://doi.org/10.1520/jte20190801
-
M. Hu, Y. Xu, S. Li, and H. Lu, “Detection of defect in ballastless track based on impact echo method combined with improved SAFT algorithm,” Engineering Structures, Vol. 269, p. 114779, Oct. 2022, https://doi.org/10.1016/j.engstruct.2022.114779
-
J. Xu, J. Zhang, and Z. Shen, “Recognition method of internal concrete structure defects based on 1D-CNN,” Journal of Intelligent and Fuzzy Systems, Vol. 42, No. 6, pp. 5215–5226, Apr. 2022, https://doi.org/10.3233/jifs-211784
-
J. Xu and X. Yu, “Pavement roughness grade recognition based on one-dimensional residual convolutional neural network,” Sensors, Vol. 23, No. 4, p. 2271, Feb. 2023, https://doi.org/10.3390/s23042271
-
F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Apr. 2017.
-
L. Bai, Y. Zhao, and X. Huang, “A CNN accelerator on FPGA using depthwise separable convolution,” IEEE Transactions on Circuits and Systems II: Express Briefs, Vol. 65, No. 10, pp. 1415–1419, Oct. 2018, https://doi.org/10.1109/tcsii.2018.2865896
-
P. Pyykkönen, S. I. Mimilakis, K. Drossos, and T. Virtanen, “Depthwise separable convolutions versus recurrent neural networks for monaural singing voice separation,” in Proceedings of the 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), p. 2020, Jul. 2020.
-
A. Vaswani et al., “Attention is all you need,” Advances in Neural Information Processing Systems, Vol. 30, 2017.
-
A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Sep. 2015.
-
Z. Niu, G. Zhong, and H. Yu, “A review on the attention mechanism of deep learning,” Neurocomputing, Vol. 452, pp. 48–62, Sep. 2021, https://doi.org/10.1016/j.neucom.2021.03.091
-
L. Kaiser, A. N. Gomez, and F. Chollet, “Depthwise separable convolutions for neural machine translation,” arXiv:1706.03059, Jun. 2017.
-
Mahdy and Amr M. S., “Stability, existence, and uniqueness for solving fractional glioblastoma multiforme using a Caputo-Fabrizio derivative,” in Mathematical Methods in the Applied Sciences, Wiley, 2023, https://doi.org/10.1002/mma.9038
-
A. M. S. Mahdy, A. S. Nagdy, K. M. Hashem, and D. S. Mohamed, “A computational technique for solving three-dimensional mixed volterra-fredholm integral equations,” Fractal and Fractional, Vol. 7, No. 2, p. 196, Feb. 2023, https://doi.org/10.3390/fractalfract7020196
-
Z. Wang and T. Oates, “Imaging time-series to improve classification and imputation,” arXiv:1506.00327, 2015.
-
G. Zhang, Y. Si, D. Wang, W. Yang, and Y. Sun, “Automated detection of myocardial infarction using a Gramian angular field and principal component analysis network,” IEEE Access, Vol. 7, pp. 171570–171583, Jan. 2019, https://doi.org/10.1109/access.2019.2955555
-
B. Han, H. Zhang, M. Sun, and F. Wu, “A new bearing fault diagnosis method based on capsule network and Markov transition field/Gramian angular field,” Sensors, Vol. 21, No. 22, p. 7762, Nov. 2021, https://doi.org/10.3390/s21227762
-
S. Liu, S. Wang, C. Hu, and W. Bi, “Determination of alcohols-diesel oil by near infrared spectroscopy based on Gramian angular field image coding and deep learning,” Fuel, Vol. 309, p. 122121, Feb. 2022, https://doi.org/10.1016/j.fuel.2021.122121
-
J. Cui, Q. Zhong, S. Zheng, L. Peng, and J. Wen, “A lightweight model for bearing fault diagnosis based on Gramian angular field and coordinate attention,” Machines, Vol. 10, No. 4, p. 282, Apr. 2022, https://doi.org/10.3390/machines10040282
-
Y. Liao, X. Qing, Y. Wang, and F. Zhang, “Damage localization for composite structure using guided wave signals with Gramian angular field image coding and convolutional neural networks,” Composite Structures, Vol. 312, p. 116871, May 2023, https://doi.org/10.1016/j.compstruct.2023.116871
-
M. Feng and J. Xu, “Detection of ASD children through deep-learning application of fMRI,” Children, Vol. 10, No. 10, p. 1654, Oct. 2023, https://doi.org/10.3390/children10101654
-
J. Xu, J. Zhang, and W. Sun, “Recognition of the typical distress in concrete pavement based on GPR and 1D-CNN,” Remote Sensing, Vol. 13, No. 12, p. 2375, Jun. 2021, https://doi.org/10.3390/rs13122375
Cited by
About this article

This research was made possible thanks to the generous financial support provided by various organizations. Specifically, we would like to acknowledge the Anhui International Joint Research Center of Data Diagnosis and Smart Maintenance on Bridge Structures under grant number 2021AHGHZD02, the Anhui Province Natural Science Foundation of China under grant number 2208085US02.
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Min Feng and Juncai Xu: conceptualization, methodology, software, validation; Min Feng and Juncai Xu: formal analysis, investigation, data curation, writing-original draft preparation; Juncai Xu and Min Feng: conceptualization, writing-review and editing, visualization, funding acquisition.
The authors declare that they have no conflict of interest.
