Abstract
The traditional mode of education has been integrated with the technologies of internet to give rise to smart and or intelligent assistant education. A recommender “recommending items to customers” has been applied with great success in many commercial platforms, such as Amazon, Google, JD.com, and Tiktok, but there still has been no such an assisted learning system that effectively “recommending exercises (as the items) to learners (as the customers)”. This paper addresses the problems and challenges in applying recommender technology to the design of an intelligence-assisted learning system for individualized exercises recommendation. After providing an overview with some analysis on state-of-the-art researches, a model is proposed to improve DINA algorithm by four adjustments with changeable parameters of cognitive level perception (CLP), together with three primary steps of implementation in practice. It aims to improve recommendation accuracy of the mostly-concerned DINA algorithm based on widely-concerned cognitive diagnosis method (CDM). The proposed algorithm would have better performances on individualized exercises recommendation due to better CLP-capability. Another part of this study will provide further verification of the performances.
1. Introduction
Rapid development on online education all over the world results in a number of platforms, such as EdX, Coursera, Udemy, and Khan Academy, etc. However, the vast amount of data resources may easily lead to the problem of “Overload Information Confuses Choice”. In 1997, Resnick firstly proposed a recommender [1], which has been continuously applied and extended to many fields in industry and commerce, and achieved significantly, such as platforms of Amazon, Google, TikTok, JD.com, and Tencent, as well as many cultural industrial platforms, recommending products or items to customers or users.
In addition, the traditional teaching mode employs indiscriminate teaching and blind training in “the sea of exercises”, and thus increases heavy burden on learners. Most exercise websites select the exercise to recommend from vast amount of online exercises by a single screening configuration, which is essentially an indiscriminate delivery and leads to low learning efficiency and poor targeting. How to accurately recommend appropriate exercises to learners is a hot problem in construction of an intelligence-assisted learning system. Although there have already been a number of researches and achievements in individualized exercises recommendation, including learner and exercise modeling, and recommendation algorithm designing, there are still lots of predicaments, such as difficult representation and insufficient perception on exercise features, difficult diagnosis on learners' status, and difficult definition on the knowledge points dynamically mastered by a learner via exercise-doing, etc. These difficulties then lead to low accuracy of exercises recommendation. The predicaments result in that, even the mostly-concerned DINA algorithm with widely-concerned CDM still has such problems of low accuracy, and inability to time-serially cognize knowledge mastery level and perceive dynamic status of learners and exercises, which are collectively referred to as ‘cognitive level perception (CLP)’ in this paper. In addition, an inherent limitation of current methods is that the implicit connections between learners (exercises) have been largely ignored, so that finer-grained portraits of learners and exercises are not encoded properly, and thus recommendation result may not be sufficient to capture “suitable” preferences and dynamic status for learners [2]. Consequently, there is still no such an assisted learning system that effectively “recommends suitable exercises (items) to learners (customers)” so far, and more R&D works are to be done.
This paper focuses on individualized exercises recommendation algorithm based on CLP. Firstly, an overview and some analysis on relevant researches are conducted. Then, centering on the mostly-concerned DINA algorithm with widely-concerned CDM, an improved model is proposed for individualized exercises recommendation by four adjustments with changeable CLP-parameters, including three steps of implementation in practice. It is reasonable to predict that the proposed model would have better performance in individualized exercises recommendation. This is to be verified by another part of this study.
2. Brief review on individualized recommending exercises
2.1. Recommending systems
The essence of a recommender is an information filtering system that can provide users or customers precise recommendation information or items without explicit user-demands, based on their preferences, habits, and or other information [3]. The main applications include e-commerce, search engine, and the cultural industry. Recommenders rely on individualized recommendation algorithms, including traditional methods, such as “content-based”, “collaborative filtering (CF, most widely-used)”, and their “hybrid” recommendations, etc. In recent years, the advantageous technology of deep learning (DL) has been increasingly favored, including two methods of modeling based on convolutional neural network (CNN) and recurrent neural network (RNN) [4,5]. Knowledge Graph (KG) launched by Google in 2012 has been widely applied in many recommenders [6]. Resulted from CNN and KG, graph convolution network (GCN) was well developed, for instance, LightGCN architecture has been considered as a more appropriate GCN in recommender design [7]. Researches on other areas are extensive and in-depth. For examples, Chen used deep belief net (DBN) and sentiment analysis to process user-comment data [8]; X. H. Wei proposed an end-to-end recommendation algorithm for social networks to improve the hit rate of recommendations [9], W. J. Chen et al proposed a knowledge cross-domain sharing recommendation model based on transfer learning [10], etc. At present, KG-based recommenders are widely used in the fields of movies, news, e-commerce, and musics. Investigations on improving performances are continuously deepening and expanding, and many achievements also provide pioneering theoretical and technical foundations for individualized exercises recommendation in smart education and its intelligence-assisted learning system.
In order to apply the relevant technologies of a recommender to individualized exercises recommendation, learner modeling, exercise modeling and algorithm designing are three critical parts of work, on which the developments are briefly reviewed next, respectively.
2.2. Modeling learner
Learner modeling is the process of accurately diagnosing (profiling) and representing a learner's cognitive capability, knowledge mastery level, and learning status (static and dynamic). By mining and extracting both explicit and potential implicit features of a learner, including basic individual information, learning preference, cognitive and knowledge mastery levels, learning behavior trait, and real-time learning need (objective), etc. These features can be effectively represented to contain rich enough individualized semantics. Currently, there are considerable researches on learner modeling, which are primarily divided into two categories: “knowledge tracking (KT)” and “cognitive diagnosis (CD)” modeling.
KT-based modeling involves constructing a model of a learner on basis of his or her cognitive style, performance in learning process, and historical answering behavior, to determine current knowledge status. There are three main methods so far:
1) “Probability Graph”-based Method. The typical representative is Bayesian KT (BKT). BKT method does not consider such factors as correlation of knowledge points and learner forgetting, resulting in low accuracy of predictions. X. G. Li [11] and Kaser et al. [12] integrated multiple features of learning process and deeply associated the relations between knowledge points to improve the accuracy. Overall, various KT methods based on probability graphs have such shortcomings as “lower accuracy, dependence on teachers’ prior teaching experience, need to manually annotating knowledge points, and a lower degree of automation”.
2) “Matrix Factorization”-based Method. Probability matrix factorization (PMF) is introduced into KT to form the KPT model [13]. The KPT model predicts better than BKT, but its extendibility is poor.
3) “Deep Learning”-based Method. Deep (learning) KT (DKT or DLKT) model does not rely on prior teaching experience or manual annotation of knowledge points [14], and its KT-effect is better than that of BKT and KPT. However, DKT model is lack of analysis in-depth on learner’s learning process and knowledge interaction, resulting in insufficient interpretability of outcomes. H. J. Li et al. [15] integrated multi-dimensional features of the process to construct a DL-based method of KT optimization, DKVMN-BORUTA, and improved the effectiveness and interpretability of KT.
CD-based learner modeling has already over 60 sorts of models [16], such as DINO, NIDA, RR-UM and C-RUM, etc. According to whether the attribute of a measured object is continuous or not, CD-models are categorized into “discrete model, e.g., item response theory (IRT)” and “continuous model, e.g., DINA (deterministic input, noisy ‘and’ gate)”. They can also classified into “binary scoring model” and “multi-level scoring model”, in terms of the number of model scoring grades. DINA is of binary scoring model. The essence of a multi-level scoring model is to model each scoring grade, thereby transform multi-level scoring into binary one. There was also learner modeling in view of contextual awareness, such as that Y. Y. Wang [17] used intelligent perception technology to integrate computational educational contexts, delve into learner features, and construct a context-aware learner model.
2.3. Modeling exercise
Exercise modeling conducts primarily semantic representation and knowledge parsing of an exercise, which contains heterogeneous and or multi-modal information such as text, images, and formulas, etc., to form a feature model of the exercise. At present, relevant researches mainly involved the modeling led by classical test theory (CTT) and the modeling based on “lexical representation, sentence representation and multi-modal deep semantic representation”. Early exercise modeling was mainly based on CTT, depending on the experiences of educational experts and manual annotations, which was time-consuming and labor-intensive with low efficiency, making it difficult for large-scale application. In recent years, applications of natural language processing (NLP) and DL technologies have enabled automatic representation of various dimensional indicators in modeling. The modelings based on lexical representation can be classified as three methods according to word representation: “One-hot, TF-IDF, and Word-vectors” [18].
One-hot and TF-IDF are simple and efficient but have shortcomings such as excessively large vector dimensions with extreme sparsity, low storage space utilization and computational efficiency, inability to consider the influence and correlation between words, and neglect of sequential information. The word-vector method starts from the perspective of mutual influence and correlation between words to explore a more efficient word representation, overcoming the shortcomings of the first two methods to some extent. But it also neglects the sequence between words and structural information of exercises. “Sentence Representation”-based modeling uses DL technologies (CNN and RNN) to deeply understand and numerically represent word information in the text of exercises at the sentence level, but in practice, it is prone to gradient disappearance or gradient explosion. Modeling on multi-modal deep semantic representation mainly addresses the semantic representation of multi-source heterogeneous information, such as text, charts, and formulas in exercises in the subjects of science and engineering. For instance, E. H. Chen [19] proposed a unified representation framework, QuesNet, for multi-source heterogeneous teaching resources, which solved the representation problem of multi-source heterogeneous exercises. However, in practice, some features will be also changed relative to the change of learner’s status. How to perceive and represent this dynamism synchronously is a problem to be solved.
2.4. Algorithms of individualized recommending exercises
An algorithm of individualized exercises recommender recommends suitable exercises to learners on the basis of matching “learner’s individualized features” with “exercises features”. So far, there are mainly CF-based algorithms [20], CDMs, and DL-based recommendation approaches. Where, CF-based algorithms can be classified as two types: Neighbor-based and Model-based. The former had achieved a certain effects of individualized recommendation [21], and the latter is widely applied by use of matrix factorization (MF) [22]. Additionally, PMF is most widely applied. However, the recommendation algorithms based on CF and PMF both have the problems of sparsity and cold-start of Q&A (or exercise-answer) matrix [7]. T. Y. Zhu et al [23] combined PMF with CDM to form a PMF-CD algorithm to improve the recommendation accuracy. R. T. Shan et al. [24] combined CDM with CF-based algorithm, achieving some improvement on recommendation accuracy. Z. Huang et al proposed a deep reinforcement learning framework – DRE, which can adaptively recommend exercises to learners [25]. H. J. Li et al. [26] deeply mined learner information for individualized resource recommendation. T. Guo et al. [27] proposed an educational resource recommendation model G-LSTM that integrates the models of general matrix factorization (GMF) and long short-term memory (LSTM), and verified its effectiveness and accuracy. In recent years, recommendations based on knowledge graphs (KG) [7] and deep reinforced learning recommendation integrating multi-modal features have also emerged [6].
3. Individualized recommending exercises by CDM
The core purpose of both CD and KT is for “assessment on learners’ status”, which was carried out by CTT at early times. To improve the CTT assessment that is not objective enough, IRT came into being and established a model function for student ability and response accuracy, including such parameters as the difficulty, discrimination, and guessing of exercises. For an IRT model, if input learners’ Q&A data and use parameter estimation, then, both parameters of the exercises and the ability values of the learners (scored 0/1) can be obtained. Constant researches have developed more and more extensions to IRT, such as multi-item response theory (MIRT), graded response model, generalized partial credit model, rating scale model, etc. These models can only provide a learner's ability value but cannot represent the specific status of learner's knowledge mastery. Therefore, theory of cognitive diagnosis has been developed, which was added the cognitive attributes, i.e., knowledge points. The commonly-used ones include rule space model (RSM), NIDA model and DINA model [28].
In the field of learner modeling and algorithm designing for individualized exercises recommendation, CDM-based algorithms with their models are widely concerned. The main types of these models include IRT and DINA models, attribute hierarchy model, and neural network CDM. Where, IRT models can be classified further into one-, two-, and three-parameter types, and DINA model is particularly favored due to its superior interpretability of results, with its improved versions including HO-DINA, P-DINA, and G-DINA, etc.[28] For example, M. Q. Liu [29] applied G-DINA model for individualized recommending math-exercises of functions at middle school. Although DINA algorithm has been paid much more attentions, it can only obtain the knowledge mastery level of learners at a single moment and cannot track the changes of learners’ CLP and exercises’ features in a process of certain time series. This is a problem of worth studying [7]. In addition, these CDM-based individualized recommendation algorithms also have lots of problems to different extents, such as “need to improve recommendation accuracy”, “Q-matrix relies on expert or manual design (time-consuming and labor-intensive)”, and “insufficient perception on dynamic changes of learners and exercises”. Researchers are continuously trying to solve these problems. For instance, A. W. Zhou [30] used a neural CDM model to obtain cognitive state level of learners in real time and then select the exercises with suitable difficulty coefficients to recommend. Similar improvements by machine learning optimization on CDM-based algorithms are ongoing all the way. For examples [31], the model of fuzzy cognitive diagnosis (FuzzyCDM), which is an improvement to DINA, introduced fuzzy logic control to achieve a continuous value for the state of knowledge mastery instead of 0/1; Knowledge plus gaming response model (KPGRM), like a neural CDM, broke away from the interaction functions defined by humans in IRT and DINA algorithms, and used a hidden layer to implement the training functions, and thus the cognitive status can be denoted by continuous value, and “knowledge mastery level” can be learned and thus applicable to large sample data.
4. Improving DINA algorithm by four adjustments with changeable CLP-parameters
CDM-based recommendation algorithms and their models have been paid lots of attention in individualized exercises recommendation, as described in Section 3. Where, both IRT and DINA have been widely concerned, and DINA algorithm seems to be the most prospective solution, due to its relative simplicity and superior interpretability on the results of recommendation. However, even for DINA algorithm and its improved versions, there are still three deficiencies as follow:
1) Inability to track learner's knowledge mastery level and perception on exercises within a certain time series, due to insufficient perception on dynamic changes of learners and exercises.
2) Low accuracy of exercise recommendation.
3) Architectural complexity of algorithm model, including those based on machine learning and or optimization.
To make up above deficiencies, here focuses on improvement of simple, easy and understandable DINA algorithm, and proposes a CLP-based solution, which cognizes better the learner's knowledge mastery level and well perceives the dynamic status of exercises within a certain time series, as defined in Section 1. The improvement is carried out by four variable parameters that adjust the two key factors of probability in DINA algorithm to obtain sufficient CLP capability, so as to form an algorithm with changeable parameter-adjusted CLP for the solution. The performances of recommending exercise should be improved.
DINA algorithm is originally to diagnose learners’ knowledge mastery status. It is based on IRT and analyzes the “Q&A” or “exercise-answer” circumstance for multi-choice exercises, from which the status of a learner is deduced. Fig. 1 simply illustrates the framework of original DINA algorithm.
DINA algorithm [32] assumes the learner either fully master the required knowledge points, or randomly guess, when dealing with an exercise, and uses a -matrix to represent all required knowledge points, , 1 or 0 denotes that exercise contains required knowledge point or not, respectively. Then, for each learner , define a vector of knowledge mastery level, , 1 or 0 denotes that learner masters knowledge point or not, respectively. Thus, status of of learner doing exercise can be represented by:
where, 1 or 0 denotes that learner does exercise correctly or incorrectly (at least one knowledge point has not been mastered). Then, under the condition of learner with knowledge mastery level , the probability of doing exercise correctly can be then obtained by conditional probabilistic computation, i.e.:
where, is the scoring of learner on exercise , which is an entry of Q&A or exercise-answer matrix , 1 denotes doing correctly, or 0 denotes doing incorrectly; The two key factors, and , are called slip factor and guess factor, respectively, which represent the probability of doing exercise incorrectly in case of learner has mastered all the required knowledge points, and the probability of guessing exercise correctly in case of learner has not mastered all the points, respectively. Therefore, once input all the data of Q&A of learners on exercises, the two factors and knowledge mastery status would be obtained by parameter estimation.
Fig. 1DINA algorithm framework
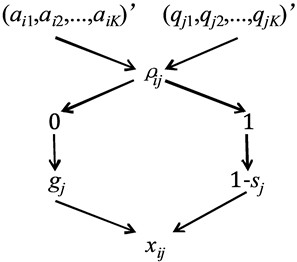
DINA algorithm has the advantages of highly efficient computation and thus capable of processing large-scale data, and providing diagnostic feedback well in detail, however, there is still a limit on its application because of only two states of knowledge mastery level, (0, 1). In addition, in practice, the statuses of both learners and exercises are not so simple - either master all knowledge points’, or “randomly guess with nothing mastered”, which may also be dynamically changed with time being.
To improve the DINA algorithm based on changeable CLP-parameters, which is to be added onto the guess- and slip-factors for learners and exercises, respectively, as shown in Fig. 1:
(1) On Guess factor : Consider that, the better the learner is, the greater the probability of guessing correctly without mastering all knowledge points. Therefore, add an variable parameter of individual aim of learner at current time serial , , e.g., 1 – higher, or 0 – lower than last time. In addition, add another variable parameter of individual attitude of learner at current time serial , , e.g., 1 – carefully, or 0 – halfheartedly doing exercises.
(2) On Slip factor : Consider that, the more difficult an exercise is, the greater the probability of doing incorrectly under the condition of mastering all the knowledge points. Therefore, add a variable parameter of exercise-difficulty, , onto the factor . Where, denotes the absolute or constant difficulty with continuous values from 0 – easy to 1 – most difficult, which can be marked by expert(s) in the field, and denotes the relative/variable difficulty of learner on exercise , with discrete values 0 – doing correctly and 1 – doing incorrectly, at current time serial number . In addition, add another parameter of exercise-classification, , where, denotes absolute or constant classification marked by expert(s) in the field, representing the category or special labeled set of exercise , and denotes relative or variable classification, 1 – to recommend, or 0 – not to recommend, after the time serial number .
In summary, the adjustments on the two factors by use of four variable parameters can be schemed in following way:
where, mark ‘’ denotes some sort of mathematical operation(s) to be predetermined by simulations and or experiments. Actually, except for the four variable parameters (, , , ), there may be some other variable parameters to be used for the adjustments, such as the representations of non-structural latent features of “memory and or forgetting” curves or factors of learners. Fig. 2 shows the overall architecture.
Fig. 2Architecture of improving DINA algorithm
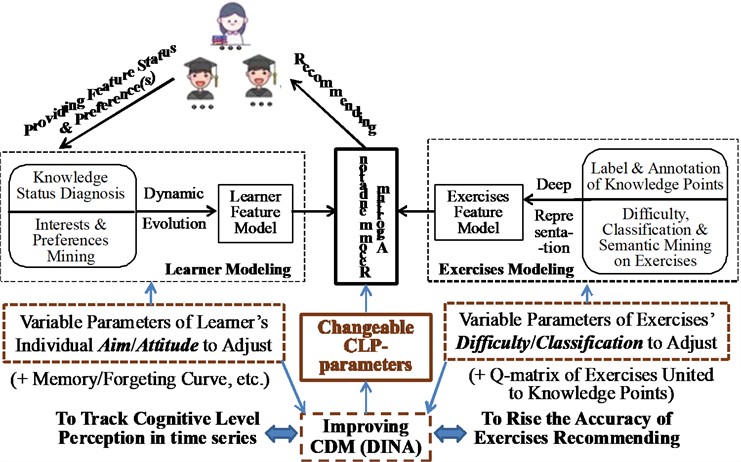
The proposed model is implemented by the following three primary steps, which can also be referred to see in Fig. 2.
Step 1: Fix the “learner-answer scoring matrix ” and “exercise-knowledge point matrix ”, which can be fixed by an initial test (or prior) answering scores’ record and expert in the field, respectively, at cold start.
Step 2: Maximize the edge likelihood of conditional probability in Eq. (3) to obtain the factors’ estimates () of by expectation maximization (EM) algorithm. And the optimal estimate of knowledge-point mastery vector, , can be obtained by maximize the posterior probability of scoring matrix [23] as:
Step 3: Once the factors’ estimates () and the optimal estimate have been obtained, put them back into Eq. (1) to compute , and then put them into Eq. (3) to compute the , in terms of which the Top-N probabilities can be listed, correspondingly, the exercises’ list () are supposed to be recommended to learner .
It is reasonable to predict that, whole performance of the proposed improved DINA algorithm would be better via the above steps of implementation than that of original DINA algorithm, including recommendation accuracy. Simulation and experimental verification on the performances will be carried out in the next part of this study.
5. Conclusions
Individualized exercises recommendation is essentially an important part of adaptive learning systems. It plays a significant role in consolidating learners’ knowledge points, diagnosing their cognitive statuses and or levels. Recommending exercises suitable for learners’ cognitive levels and abilities could stimulate and cultivate their learning motivation, and improve their learning enthusiasm and persistence. Although existing research on the theory and application of individualized exercises recommendation have obtained a certain achievements and effects, there are still many challenges in practice on next three critical areas:
1) In exercise modeling, how to further achieve deep semantic representation of cross-modal exercises, deeply mine exercise features, and use such generative AI-technology as ChatGPT for in-depth semantic annotation, thereby reduce manual annotation and improve modeling efficiency, are all to be studied. Additionally, some exercise-features may change with dynamic status of learners, how to synchronously perceive and represent this dynamism and embed them into the corresponding algorithm is also a problem worth studying.
2) In learner modeling, how to establish a theoretical system with multi-dimensional ability of cognitive diagnosis is to be investigated to combine static and dynamic learning-status perceptions.
3) In exercises recommendation algorithm, how to ensure the interpretability, meanwhile, further improve the accuracy of recommendation is always an ongoing target.
These problems and challenges are to be well faced with much efforts. Constructing a practically efficient individualized exercises recommender still need more in-depth investigations and effective works.
Centering at CDM-based individualized exercises recommendation, this study has proposed a solution model with changeable CLP-based algorithm, together with three steps of implementation. It is reasonable to predict that, whole performance of the proposed model would become better than that of DINA algorithm, including recommendation accuracy, due to better CLP on both static and dynamic changes of learners and exercises. These will be conducted and verified by another part work of this study.
References
-
P. Resnick and H. R. Varian, “Recommender systems,” Communications of the ACM, Vol. 40, No. 3, pp. 56–58, Mar. 1997, https://doi.org/10.1145/245108.245121
-
W.-W. Gao, H.-F. Ma, Y. Zhao, J. Wang, and Q.-H. Tian, “Enhancing personalized exercise recommendation with student and exercise portraits,” Journal of Electronic Science and Technology, Vol. 22, No. 2, p. 100262, Jun. 2024, https://doi.org/10.1016/j.jnlest.2024.100262
-
G. Adomavicius and A. Tuzhilin, “Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions,” IEEE Transactions on Knowledge and Data Engineering, Vol. 17, No. 6, pp. 734–749, Jun. 2005, https://doi.org/10.1109/tkde.2005.99
-
R. Xing, “Design and research of online examination system of test questions recommendation based on neural graph model,” Master’s Thesis of Jilin University, Jilin University, Chang Chun, China, 2020.
-
Y. L. Cheng and A. P. Tan, “Summary of research on personalized test recommendation,” The Journal of Hunan Post and Telecommunication College, Vol. 22, No. 2, pp. 50–55, Jun. 2023, https://doi.org/10.3969/j.issn.2095-7661.2023.02.013
-
X. C. Dang, “Research on individualized question recommendation based on knowledge graph,” Master’s Thesis of Xi’an University of Technology, Xi’an, China, 2021.
-
X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, “LightGCN: Simplifying and powering graph convolution network for recommendation,” in SIGIR ’20: The 43rd International ACM SIGIR conference on research and development in Information Retrieval, pp. 639–648, Jul. 2020, https://doi.org/10.1145/3397271.3401063
-
R.-C. Chen and Hendry, “User rating classification via deep belief network learning and sentiment analysis,” IEEE Transactions on Computational Social Systems, Vol. 6, No. 3, pp. 535–546, Jun. 2019, https://doi.org/10.1109/tcss.2019.2915543
-
X. H. Wei, B. Y. Sun, and J. X. Cui, “Recommendation algorithm for interest activity based on graph neural networks,” Journal of Jilin University, Vol. 50, No. 1, pp. 278–284, Jan. 2021, https://doi.org/10.13229/j.cnki.jdx
-
W. J. Chen and J. J. Yang, “Cross-domain recommendation study based on shared knowledge transfer learning,” Information Science, Vol. 38, No. 6, pp. 126–132, Jun. 2020, https://doi.org/10.13833/j.issn.1007-7634.2020.06.018
-
X. G. Li, S. Q. Wei, X. Zhang, Y. F. Du, and G. Yu, “LFKT: Deep knowledge tracing model with learning and forgetting behavior merging,” Journal of Software, Vol. 32, No. 3, pp. 818–830, Mar. 2021, https://doi.org/10.13328/j.cnki.jos.006185
-
T. Kaser, S. Klingler, A. G. Schwing, and M. Gross, “Dynamic Bayesian networks for student modeling,” IEEE Transactions on Learning Technologies, Vol. 10, No. 4, pp. 450–462, Oct. 2017, https://doi.org/https://doi.org/10.1109/tlt.2017.2689017
-
Y. Chen et al., “Tracking knowledge proficiency of students with educational priors,” in CIKM ’17: ACM Conference on Information and Knowledge Management, pp. 989–998, Nov. 2017, https://doi.org/10.1145/3132847.3132929
-
T. Y. Liu, W. Chen, L. Chang, and T. L. Gu, “Research advances in the knowledge tracing based on deep learning,” Journal of Computer Research and Development, Vol. 59, No. 1, pp. 81–104, Jun. 2021, https://doi.org/10.7544/issn1000-1239.20200848
-
H. J. Li, J. Q. Lu, and J. M. Wu, “Deep knowledge tracing method incorporating learning process characteristics,” Journal of Zhejiang University of Technology, Vol. 50, No. 3, pp. 245–252, Jun. 2022.
-
L. V. Dibello, L. A. Roussos, and W. Stout, “A review of cognitively diagnostic assessment and a summary of psychometric models,” Handbook of Statistics, Vol. 26, No. 6, pp. 979–1030, Dec. 2006.
-
Y. Y. Wang and Y. H. Zheng, “Learner modeling based on context awareness: connotation, feature model and practical framework,” Journal of Distance Education, Vol. 269, No. 2, pp. 66–74, Mar. 2022, https://doi.org/10.15881/j.cnki.cn33-1304/g4.2022.02.008
-
Z. Huang, “Research of exercise modeling and application based on multi-modal learning,” Master’s Thesis of University of Science and Technology of China, He Fei, China, 2019.
-
E. H. Chen et al., “Key techniques and application of intelligent education oriented adaptive learning,” CAAI Transaction on Intelligent Systems, Vol. 16, No. 5, pp. 886–898, Sep. 2021, https://doi.org/10.11992/tis.202105036
-
X. Su and T. M. Khoshgoftaar, “A survey of collaborative filtering techniques,” Advances in Artificial Intelligence, Vol. 2009, No. 1, pp. 1–19, Oct. 2009, https://doi.org/10.1155/2009/421425
-
A. Walker, M. M. Recker, and K. Lawless, “Collaborative information filtering: A review and an educational application,” International Journal of Artificial Intelligence in Education, Vol. 14, No. 1, pp. 1–26, Jan. 2004.
-
X. Z. Tian and J. Shen, “Personalized recommendation based on probabilistic matrix factorization in big data environment,” Computer Science, Vol. 44, No. 6A, pp. 438–441, Jun. 2017.
-
T. Y. Zhu et al., “Cognitive diagnosis based personalized question recommendation,” Chinese Journal of Computers, Vol. 40, No. 1, pp. 176–191, Jan. 2017.
-
R. T. Shan, Y. C. Luo, and Y. Sun, “Collaborative filtering algorithm based on cognitive diagnosis,” Computer Systems and Applications, Vol. 27, No. 3, pp. 136–142, Feb. 2018, https://doi.org/10.15888/j.cnki.csa.006239
-
Z. Huang et al., “Exploring multi-objective exercise recommendations in online education systems,” in CIKM ’19: The 28th ACM International Conference on Information and Knowledge Management, pp. 1261–1270, Nov. 2019, https://doi.org/10.1145/3357384.3357995
-
H. J. Li, Z. Zhang, H. D. Guo, and D. Wang, “Personalized learning resource recommendation from the perspective of deep learning,” Modern Distance Education Research, Vol. 31, No. 4, pp. 94–103, Jul. 2019, https://doi.org/10.3969/j.issn.1009-5195.2019.04.011
-
T. Guo, Y. Wen, F. Wang, and J. Hou, “Learning resource recommendation based on generalized matrix factorization and long short-term memory model,” in IEEE International Conference on Cloud Computing Technology and Science (CloudCom), pp. 217–222, Dec. 2019, https://doi.org/10.1109/cloudcom.2019.00040
-
X. Zhang and R. X. Sha, “Research advance in DINA model of cognitive diagnosis,” Measurement and Assessment, pp. 32–37, 2013, https://doi.org/10.19360/j.cnki.11-3303/g4.2013.01.005
-
M. Q. Liu, “Research on cognitive diagnosis of high school students’ function learning based on G-DINA model,” Master’s Thesis at Central China Normal University, Central China Normal University, Wuhan, China, 2022.
-
A. W. Zhou, “Research on individualized test items recommendation based on neural cognitive diagnosis model,” Master’s Thesis of Northwest Normal Univeristy, Lan Zhou, China, 2021.
-
Q. Liu et al., “Fuzzy cognitive diagnosis for modelling examinee performance,” ACM Transactions on Intelligent Systems and Technology, Vol. 9, No. 4, pp. 1–26, Jul. 2018, https://doi.org/10.1145/3168361
-
de La Torre and Jimmy, “DINA model and parameter estimation: A didactic,” Journal of Educational and Behavioral Statistics, Vol. 34, No. 1, pp. 115–130, Mar. 2009, https://doi.org/10.3102/1076998607309474
About this article

This study was financially supported by 2024 Guangdong Provincial Science and Technology Innovation Strategy Special Fund (College Students’ S&T Innovation Cultivation) (Project No. PDJH 2024B015) and National College Students' Innovation and Entrepreneurship Training Program (Project No. 202410558102).
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Yuhan Lyu contributed the review on the research, methodology of the proposed solution model, manuscript preparation and writing. Wei Liu contributed overall framework of the draft, revision on the proposed solution. Jianxing Yu contributed the summary on state-of-the-art. Jian Yin contributed verification on the reality of the overview and feasibility of the solution model.
The authors declare that they have no conflict of interest.
This study does not involve living organisms.
