Abstract
Artificial neural networks are becoming more popular with the development of artificial intelligence. These networks require large amounts of data to function effectively, especially in the field of computer vision. The quality of an object detector is primarily determined by its architecture, but the quality of the data it uses is also important. In this study, we explore the use of novel data set enhancement technique to improve the performance of the YOLOv5 object detector. Overall, we investigate three methods: first, a novel approach using synthetic object replicas to augment the existing real data set without changing the size of the data set; second - rotation augmentation data set propagating technique and their symbiosis, third, only one required class is supplemented. The solution proposed in this article improves the data set with a help of supplementation and augmentation. Lower the influence of the imbalanced data sets by data supplementation with synthetic yeast cell replicas. We also determine the average supplementation values for the data set to determine how many percent of the data set is most effective for the supplementation.
1. Introduction
Computer vision in micro-robotics [1] is a challenging task as images and video streams in such settings are usually low resolution and may prove difficult to be used for identifying objects of various classes [2], [3]. Furthermore, the gathering of real yeast cell images can be a difficult and very time-consuming task as it includes the preparation of yeast solution and manual acquisition of data in a controlled environment [4]. Therefore, we explore if a combination of raw and supplemented synthetic data can improve the precision of yeast cell detection and ease the data preparation process.
With the recent progress in the field of artificial intelligence [5], new perspectives have arisen in numerous directions. One of the most studied and applied topics is connected to computer vision-related problems for example in industrial robot control [6], [7]. Even though the precision of AI-based computer vision solutions has been remarkably improved in the last decade [8], [9], several drawbacks can be observed when the training data is hard to obtain. One of the problems, in this case, is connected to imbalanced classes in the training data sets. Such situations can arise in many real-world problems, for example, in disease diagnostics as the cases of the disease usually are rare compared to healthy samples [10]. Most machine learning algorithms are designed to maximize accuracy when the number of samples in each class is about equal. Therefore, typically the imbalance in classes leads to comparatively high accuracy in predicting the majority class but fails to accurately detect the minority class [11]. Currently, this challenge has been tackled by oversampling and different learning techniques [12], generative adversarial networks [13], [1], or fully synthetically generated datasets [15], [16]. In this article, we explore how class supplementation with synthetic object replicas can increase the precision of object detection tasks. In essence, the problem we are dealing with in this article is connected to these low-ranking classes that are poorly detected by the object detector or not detected at all. The aim is to increase the detection precision of low-performing classes by supplementing synthetic replicas into existing images. Moreover, the research is supplemented by analyzing how the augmentation of synthetic yeast cells can contribute to increasing the precision of this task. In addition, the detection precision is directly connected to the precision of a micro-robot trajectory, where the key points in the trajectory e.g., manipulation position, approach and retreat positions directly depend on the results of the yeast cell detection task.
2. Proposed approach
2.1. Object replica supplementation
As many machine learning algorithms are designed to maximize overall accuracy, the minority classes tend to achieve remarkably lower results. In this research, the number of underrepresented objects in training data sets is artificially increased to improve the accuracy of the object detector. The data sets are also additionally augmented to further increase the accuracy. These techniques are the basis of this article and complement each other in an accuracy improvement.
2.2. Synthetic data
2.2.1. Data generation and augmentation
For image generation, the free and open-source 3D creation software Blender is used. It supports the entirety of the 3D pipeline – modelling, rigging, animation, simulation, rendering, compositing and motion tracking, video editing and 2D animation pipeline.
Fig. 1Synthetic object replica generation process: a) synthetic object preforms, b) generated synthetic objects (random scale, rotation)
The whole generation process can be divided into three phases- creating preforms, alteration of said preforms and blurring. All phases of the process are visualized in Fig. 2 using yeast cell images as reference.
In the first phase, visible in Fig. 2(a), the preforms are created similar in size and proportion to the real objects seen in real-world data. They are created consisting of smaller points in their outline so they could be easily altered in the following phase.
The second phase, Fig. 2(b), is the alteration of the preform. This is done to make the data appear more realistic. The object is altered by many different manipulations in an automated process, but to a degree, so that the object would still appear as close to real data as possible.
The third phase, Fig. 2(c), consists of blurring the object and placing it on the real image. The blurring is done to completely blend the two making it appear as real as possible. This can be done in many ways, for example, using algorithms or image editing software. The blurring technique is dependent on the specific image generated, so for better results, an object detector that focuses more on the shape and relationship of the objects rather than specific colours is to be used.
Fig. 2Synthetic object replica generation and augmentation process: a) first phase, b) second phase, c) third phase

Fig. 3Block diagram describing the training and validation data set’s augmentation
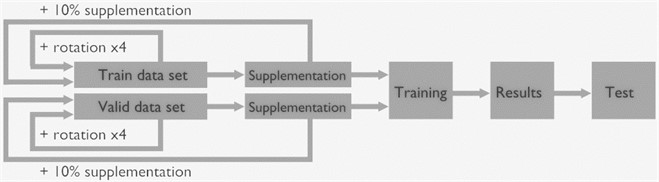
Round objects have an advantage over those of different shapes in that when augmented by rotation, it can be easily done within their bounding box. In this way, the original size and boundary stay the same. The process behind the augmentation of the data set used in this article is illustrated in Fig. 3.
2.2.2. Supplementation
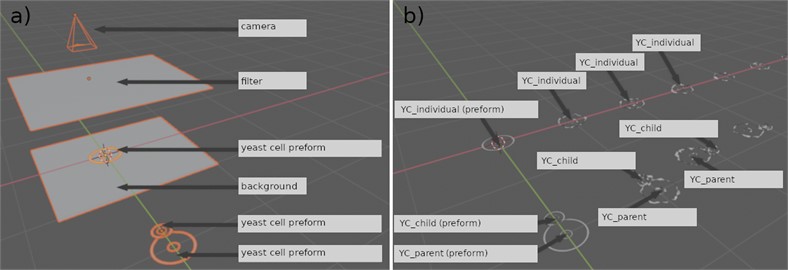
The process of supplementing synthetic object replicas into real-world images can be accomplished through various approaches, including the three-dimensional gravitational method, manual insertion, and fully automated supplementation. This paper focuses on the three-dimensional gravitational method, which involves several steps carried out in Blender. The first step in this method is importing real, labelled images into Blender, as shown in Fig. 4(a, d). The labelled objects in these images are then automatically converted into passive 3D objects, either in cube or sphere form, as visible in Fig. 4(b, e, c, f). This conversion ensures that the synthetic objects don't overlap with the labelled objects, and it also adds a factor of randomness to the process. The next step involves adding the synthetic data, which is generated according to the approach described in Section 2.2.1. A three-dimensional gravitational method is used, synthetic objects are spawned above the image and dropped using gravity simulation. The physics engine in Blender calculates the motion of these objects under the influence of gravity, taking into account their mass and the force of gravity. The previously extruded, labelled objects in the real image ensure that the synthetic ones don’t overlap with them, and the physics simulation adds a factor of randomness to the supplementation process. Blender also allows for the customization of the physics simulation, including adjusting the strength of gravity, the friction of surfaces, and the collision properties of objects. This enables users to fine-tune the physics simulation to achieve their desired results. In the final step, the generated data is acquired as an image for further use. The imported background image is deleted, leaving only transparent synthetic data. These images are then blurred and placed on their respective real images and saved.
Fig. 4 illustrates the supplementation process using screenshots from Blender. Fig. 4(a) shows the original image from the microscope, while Fig. 4(b, c) and (e, f) show the tagged objects in the 3D environment with the boundary beams in cube and sphere form, respectively, stretched along the axis. Fig. 4(d, e, f) shows how the 3D environment is used to add object replicas into existing images, rotated by 20 degrees along the and axes.
While the three-dimensional gravitational method is effective, it is not the only approach for supplementing synthetic object replicas into real-world images. The manual method requires the user to insert each synthetic object replica manually, which is time-consuming. The fully automated method, on the other hand, is an algorithmic method that automatically inserts the generated synthetic object in free spaces.
Fig. 4Supplementation process of synthetic object replicas
2.3. Training setup
A wide variety of machine learning algorithms are currently available to detect objects in images. At the beginning of the study, YOLOv5 was one of the most popular real-time, single-stage object detection algorithms with the best AP scores and FPS trade-offs [17], which is why it was used for all the following experiments. YOLOv5 is a family of object detection architectures and models pretrained on the COCO data set. Training and evaluation were performed on Linux OS workstations with A100 GPUs.
3. Experimental setup
The experimental setup is connected to an important issue in automated equipment for living cell manipulation where the detection of living cells highly dictates the precision of the whole system. To perform a manipulation task the end-effector of the automated equipment or, in this case, a microrobot, must be positioned close to the cell, therefore exact location of the cell must be found, with a typical precision of micrometres. The living cells are mostly placed in growth mediums, which are transparent therefore increasing the difficulty of the object detection task. Furthermore, the gathering of real yeast cell images for training purposes can be a difficult and very time-consuming task. It includes the preparation of a yeast solution, which often requires more effort and competencies from the researchers than the research itself. Also, the data has to be manually acquired in a controlled environment, which can result in some classes being underrepresented, therefore resulting in an overall worse dataset. Yeast cell (Saccharomyces cerevisiae) is a very common and cheap live cell material, available in the market. In addition to that, yeast cells are very strong mechanically [18] and can survive in harsh conditions; they can hibernate in the dry state and revive in favourable ambient conditions. The size of these cells is about 5 micrometres, and they are round in shape, therefore our choice falls to these live single-cell organisms. For the training of the manipulation systems and trial of various manipulation methods yeast cells seem very suitable objects.
3.1. Data acquisition
An original design four-axis micro-robot with scanning electrochemical microscope possibilities was used for the experiments. It consists of the following core modules: mechanical manipulating system, optical system, motion controller, electrochemical signal reader, and main control unit. The main controller, which is realized on a PC, generally controls the system, runs the user interface and generates robot movement trajectory and measurement commands. They are used by the motion controller and signal reader. Lower-level controllers and devices perform the more specific tasks assigned to them. The hardware for this task was the original design of the manipulating system with the microscope. The mechanical system of the developed microscope has four degrees of freedom. It is based on the kinematic scheme of the typical orthogonal manipulator like a 3D printer or similar CNC machine. An optical microscope made from cast iron was used as a housing for the device to ensure high thermal stability and sufficient stiffness. During the redesign, new precisely controlled drives were installed, simultaneously maintaining their minimal position deviation ensured by the precisely machined fixing point on the microscope base. As a result, an orthogonal manipulation system with a movable table (- axes) and two parallel -axes was developed. The first -axis is used to control the focal distance of the optical microscope. The second one moves the electrode or any sensor or gripper up and down. The optical microscope and the measuring electrode are mounted on separate parallel axes due to the need for asynchronous motion. The and -axis have a resolution of about 1 micrometre and control the movements of the table on which the test specimen is placed. -axes have a resolution of about 0.75 micrometres. The high accuracy and resolution of the drives are ensured by using micrometre’s pitch ball-screw drives controlled by stepper motors operating at 1/256 micro-step mode and advanced control methods. Therefore, using commercially available modules, relatively low-cost components, design, and software solutions proven in other fields and an original control and data fusion algorithm, automated scanning of the microscopic size biological or technical objects was utilized in the data acquisition process.
3.2. Yeast cell classes
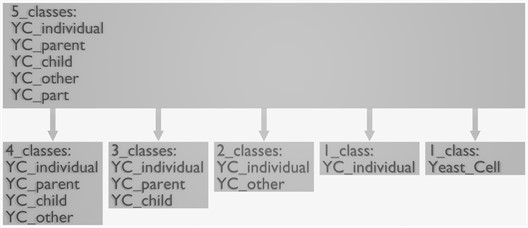
The primary class, the highest in priority to detect in this study is the individual class of the yeast cell (YC_individual). As a result of biological processes, other classes of these objects are derived from this class. The different derivations of these classes are listed in Fig. 5. In essence, every combination contains this individual yeast cell, however, we change how we address the remaining yeast cells. Overall, the different impacts on the detection results made by the various classes are investigated and compared with the results achieved using supplementation of underrepresented classes.
Fig. 5Different breakdowns of the data set from most detailed to the most abstract
4. Tests and results
Three approaches were explored for this research. A supplementation of under-represented classes, a supplementation of under-represented classes with rotational augmentation, and a supplementation of classes of interest.
4.1. Data sets
Data sets are in different ratios, to experimentally evaluate if the ratio has an impact on the precision of the object detection. In the beginning, the training data sets consist of 70 raw images only. On every iteration, the percentage of supplemented images in the data set is increased by 10 % until the data set is 100 % supplemented images. The same gradual replacement is also applied to the validation data set. In total 200 raw images were used, 70 for training (unaltered, raw images), 70 were devoted to supplementation purposes, 30 for validation and 30 for testing.
4.1.1. Supplementation of under-represented classes with and without rotational augmentation
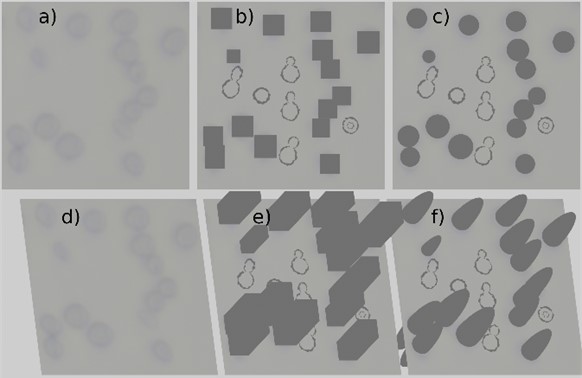
Fig. 6Images for the under-represented classes data set

a) Raw image

b) Synthetic image

c) Supplemented image
Table 1Objects in data sets for underrepresented classes
Percent of supplemented images | YC_individual | YC_parent | YC_child | YC_group | YC_other |
0 % | 655 | 85 | 85 | 917 | 492 |
20 % | 683 | 152 | 152 | 917 | 492 |
40 % | 712 | 220 | 220 | 917 | 492 |
60 % | 740 | 290 | 290 | 917 | 492 |
80 % | 768 | 360 | 360 | 917 | 492 |
100 % | 798 | 430 | 430 | 917 | 492 |
The data set was supplemented with objects from 3 under-represented classes: YC_individual, YC_parent, and YC_child. The number of objects per image is two YC_individual objects, five YC_parent and five YC_child objects.
4.1.2. Supplement of classes of interest
Fig. 7(a) illustrates a raw image from the small-scale objects data set, Fig. 7(b) illustrates an image from the small-scale object's data set with supplemented objects, Fig. 7(c) illustrates a raw image from the large-scale object's data set and Fig. 7(d) illustrates an image from the large-scale object’s data set with supplemented objects. Images were supplemented with objects representing the YC_individual class.
Fig. 7Images for classes of interest data set: a) raw image objects, b) supplemented objects, c) raw image, d) supplemented objects
Table 2Objects in data sets for classes of interest
Object size = 115×115 pixels | ||||
Small-scale objects data set | YC_individual | YC_group | YC_part | Total objects |
Raw data set | 140 | 150 | 120 | 410 |
Supplemented data set | 280 | 150 | 120 | 550 |
Object size = 230×230pixels | ||||
Large-scale objects data set | YC_individual | YC_group | YC_part | Total objects |
Raw data set | 650 | 1080 | 470 | 2200 |
Supplemented data set | 1350 | 1080 | 470 | 2900 |
4.2. Evaluation metrics
The detection is primarily evaluated using mean Average Precision (mAP) parameters. mAP@50 is the mean average precision with an IOU (Intersection Over Union) of 0.5. mAP@50-95 is the mean average precision with an IOU of 0.5 with step 0.05 till 0.95. Precision = True Positive / (True Positives + False Positives). Recall = True Positives / (True Positives + False Negative). Metrics like mAP@50 and mAP@50-95 allow to quickly see improvements and give a complete picture of the effectiveness of data sets [19]. mAP@50 and mAP@50-95 are absolute metrics, while precision and recall are relative metrics. mAP@50 is the official VOC [20] metric and mAP@50-95 is the official COCO metric [21].
4.3. Results
To train and test the effects of supplementation, the training and validation data sets were also supplemented and augmented by rotation. In such a way as to verify and subtract a single set of data. In total 3 subsets were evaluated to study different aspects and respective results of the supplementation. For supplementation of classes of interest, two data sets of objects of various sizes (small-scale and large-scale objects data sets) were also studied, and YOLO models were trained and evaluated.
4.3.1. Supplementation of under-represented classes
Fig. 8 illustrates the achieved results of the data set supplementation with object replicas of underrepresented classes with the metric mAP@50. Supplementation without rotation augmentation is illustrated with dashed lines and data with 5-time rotation augmentation with continuous lines. Supplementation was done with a step of 10 %. Even though on average the precision increase is observed through all the classes when the rotational augmentation is applied, the highest precision increase can be observed for the under-represented classes.
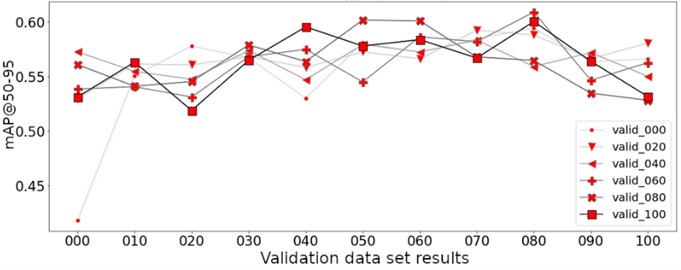
Fig. 9 illustrates the achieved results of the data set supplementation with synthetic object replicas of underrepresented classes such as YC_individual, YC_parent, and YC_child with the metric mAP@50-95. The validation dataset was also supplemented. The supplementation step was 20 %. All the variations when the validation data set is supplemented with synthetically generated yeast cells show higher precision ratings when compared to the baseline where no training nor the validation data was supplemented.
Fig. 8mAP@50 for detecting objects with 5 classes, without rotation augmentation, with rotation augmentation = x5
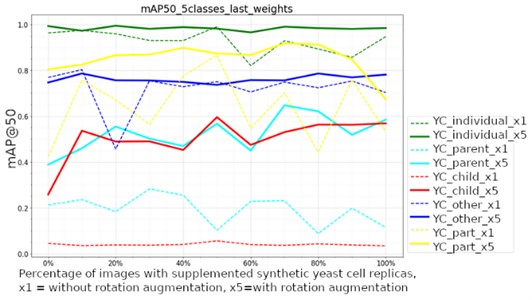
Fig. 9Average results at mAP@50-95 for validation data set supplemented by step of 20 percent
4.3.2. Results supplementation of classes of interest
This subsection describes the achieved results of an approach where only objects in the class of interest are supplemented. The primary class, that is the highest priority to detect is the yeast cell individual, we called it YC_individual. There are also two other classes, YC_group, where multiple yeast cells are close together and YC_part for partially visible yeast cells. Supplementation is only done for the YC_individual class. The distribution of classes is shown in Fig. 5 and in Table 2.
Fig. 10mAP@50 for detecting objects with 3 classes
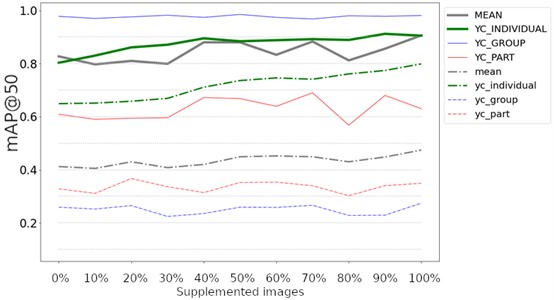
Fig. 10 illustrates the achieved results of the experiment where real-world images were supplemented with synthetic yeast cell replicas, with the supplementation step of 10 %. Solid lines are for the results of the large-scale object dataset, however, the dashed lines are from the results of the small-scale object data set, thus the mean results are illustrated with grey lines. Overall, the improvement is visible from the first supplementation step. Notably, the large-scale dataset achieved a remarkably higher precision rating than the small-scale dataset.
5. Conclusions
Imbalanced data sets can lead to decreased detection precision in the minority classes. In real-world scenarios, such imbalance in data set classes is a well-known problem, and the possible solutions can vary across different use cases. Data sets that require primary detection of one of the classes are also characteristic. In the experiments performed in this article, we approach these problems by supplementing real data with synthetically generated object replicas.
For small-scale data sets, supplementation with synthetic object replicas is a difficult and time-consuming task. Small-scale data sets require a careful, almost individual approach to supplementing each image with object replicas for good results. The supplemented images must be as realistic as possible for the best possible results. The smaller the objects are in the data sets, the greater the number of supplemented objects should be for better results. Supplementing a data set of large-scale objects with synthetic object replicas is a much more efficient task and the results are also more rewarding from a smaller amount of supplemented object replicas.
In the experimental setup, we test our approach on yeast cells. As it is rather difficult to obtain real yeast cell images, such imbalance in the data sets naturally arises, however, the precision of the detection of these cells should be equal among all the classes. In experiments with real-world data, the imbalance is observed and, thus, the detection precision for minority classes is rather poor. By supplementing the real-world data with additional synthetic objects from classes that originally have been underrepresented we observe an increase in the overall precision of object detection. The study found that supplementing the data with underrepresented classes and objects, as well as using rotational augmentation, improved the precision of the object detection task. The improvement was greater for the data set that included rotational augmentation. In cases where the data was not augmented and was small, increasing the validation data set with supplemented images had a significant impact on the improvement. However, when the data set was larger, the effect of supplementing the validation data set was less pronounced. Overall, the supplementation and augmentation techniques were effective for all data classes and data sets.
Also, precision improvements were achieved when only the class of interest was supplemented. With the supplementation step of 10 %, improvements were observed in each step of the supplementation. Adding synthetic data to real data requires testing to find the peak of precision, as adding more synthetic images can result in lower precision. Even though the performed tests have been described with the yeast cells, the proposed approach is object agnostic and can be extended to different use cases by respective image generation. Overall, in this study, we have achieved more precise object detection which serves for increased precision of microrobot trajectory key points.
References
-
V. Bucinskas et al., “Improving industrial robot positioning accuracy to the microscale using machine learning method,” Machines, Vol. 10, No. 10, p. 940, Oct. 2022, https://doi.org/10.3390/machines10100940
-
N. Dietler et al., “A convolutional neural network segments yeast microscopy images with high accuracy,” Nature Communications, Vol. 11, No. 1, pp. 1–8, Nov. 2020, https://doi.org/10.1038/s41467-020-19557-4
-
V. Bučinskas, J. Subačiūtė-Žemaitienė, A. Dzedzickis, and I. Morkvėnaitė-Vilkončienė, “Robotic micromanipulation: a) actuators and their application,” Robotic Systems and Applications, Vol. 1, No. 1, pp. 2–23, Jun. 2021, https://doi.org/10.21595/rsa.2021.22071
-
F. N. Arroyo-López, S. Orlić, A. Querol, and E. Barrio, “Effects of temperature, pH and sugar concentration on the growth parameters of Saccharomyces cerevisiae, S. Kudriavzevii and their interspecific hybrid,” International Journal of Food Microbiology, Vol. 131, No. 2-3, pp. 120–127, May 2009, https://doi.org/10.1016/j.ijfoodmicro.2009.01.035
-
C. Zhang and Y. Lu, “Study on artificial intelligence: The state of the art and future prospects,” Journal of Industrial Information Integration, Vol. 23, p. 100224, Sep. 2021, https://doi.org/10.1016/j.jii.2021.100224
-
A. Dzedzickis, J. Subačiūtė-Žemaitienė, E. Šutinys, U. Samukaitė-Bubnienė, and V. Bučinskas, “Advanced applications of industrial robotics: new trends and possibilities,” Applied Sciences, Vol. 12, No. 1, p. 135, Dec. 2021, https://doi.org/10.3390/app12010135
-
J. Arents and M. Greitans, “Smart industrial robot control trends, challenges and opportunities within manufacturing,” Applied Sciences, Vol. 12, No. 2, p. 937, Jan. 2022, https://doi.org/10.3390/app12020937
-
K. Han et al., “A survey on vision transformer,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 45, No. 1, pp. 87–110, Jan. 2023, https://doi.org/10.1109/tpami.2022.3152247
-
S. Minaee, Y. Y. Boykov, F. Porikli, A. J. Plaza, N. Kehtarnavaz, and D. Terzopoulos, “Image segmentation using deep learning: a survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 44, No. 7, pp. 1–1, 2021, https://doi.org/10.1109/tpami.2021.3059968
-
A. N. Tarekegn, M. Giacobini, and K. Michalak, “A review of methods for imbalanced multi-label classification,” Pattern Recognition, Vol. 118, p. 107965, Oct. 2021, https://doi.org/10.1016/j.patcog.2021.107965
-
N. A. B. Ramli, M. J. B. M. Jamil, N. N. B. Zhamri, and M. A. Abuzaraida, “Performance of supervised learning algorithms on imbalanced class datasets,” Journal of Physics: Conference Series, Vol. 1997, No. 1, p. 012030, Aug. 2021, https://doi.org/10.1088/1742-6596/1997/1/012030
-
Y. Pristyanto, A. F. Nugraha, I. Pratama, A. Dahlan, and L. A. Wirasakti, “Dual approach to handling imbalanced class in datasets using oversampling and ensemble learning techniques,” in 15th International Conference on Ubiquitous Information Management and Communication (IMCOM), 2021.
-
H. Yang and Y. Zhou, “Ida-Gan: A novel imbalanced data augmentation gan,” in 25th International Conference on Pattern Recognition (ICPR), Jan. 2021, https://doi.org/10.1109/icpr48806.2021.9411996
-
H. Bhagwani, S. Agarwal, A. Kodipalli, and R. J. Martis, “Targeting class imbalance problem using gan,” in 5th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), 2021.
-
J. Arents, B. Lesser, A. Bizuns, R. Kadikis, E. Buls, and M. Greitans, “Synthetic data of randomly piled, similar objects for deep learning-based object detection,” Image Analysis and Processing – ICIAP 2022, pp. 706–717, 2022, https://doi.org/10.1007/978-3-031-06430-2_59
-
Z. Kowalczuk and J. Glinko, “Training of deep learning models using synthetic datasets,” in Intelligent and Safe Computer Systems in Control and Diagnostics, pp. 141–152, 2023, https://doi.org/10.1007/978-3-031-16159-9_12
-
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 39, No. 6, pp. 1137–1149, Jun. 2017, https://doi.org/10.1109/tpami.2016.2577031
-
I. Morkvėnaitė-Vilkončienė et al., “Evaluation of yeast mechanical properties by atomic force microscopy,” 2020 IEEE Open Conference of Electrical, Electronic and Information Sciences (eStream), pp. 1–4, 2020.
-
S. S. A. Zaidi, M. S. Ansari, A. Aslam, N. Kanwal, M. Asghar, and B. Lee, “A survey of modern deep learning based object detection models,” Digital Signal Processing, Vol. 126, p. 103514, Jun. 2022, https://doi.org/10.1016/j.dsp.2022.103514
-
M. Everingham, L. van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International Journal of Computer Vision, Vol. 88, No. 2, pp. 303–338, Jun. 2010, https://doi.org/10.1007/s11263-009-0275-4
-
T.-Y. Lin et al., “Microsoft COCO: common objects in context,” in Computer Vision – ECCV 2014, pp. 740–755, 2014, https://doi.org/10.1007/978-3-319-10602-1_48
About this article

This project has received financial support from the Research Council of Lithuania (LMTLT), No. P-LLT-21-6, State Education Development Agency of Latvia, No. LV-LT-TW/2021/8, and Ministry of Science and Technology (MOST) of Taiwan, No. MOST 110-2923-E-011-006-MY3.
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Modris Laizans: conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing-original draft preparation, writing-review and editing, visualization; Janis Arents: methodology, data curation, writing-original draft preparation, writing-review and editing, supervision; Oskars Vismanis: methodology, data curation, writing-original draft preparation, writing-review and editing; Vytautas Bučinskas: resources, writing-review and editing, funding acquisition; Andrius Dzedzickis: resources, writing-review and editing; Modris Greitans: writing-review and editing, supervision, project administration, funding acquisition.
The authors declare that they have no conflict of interest.
